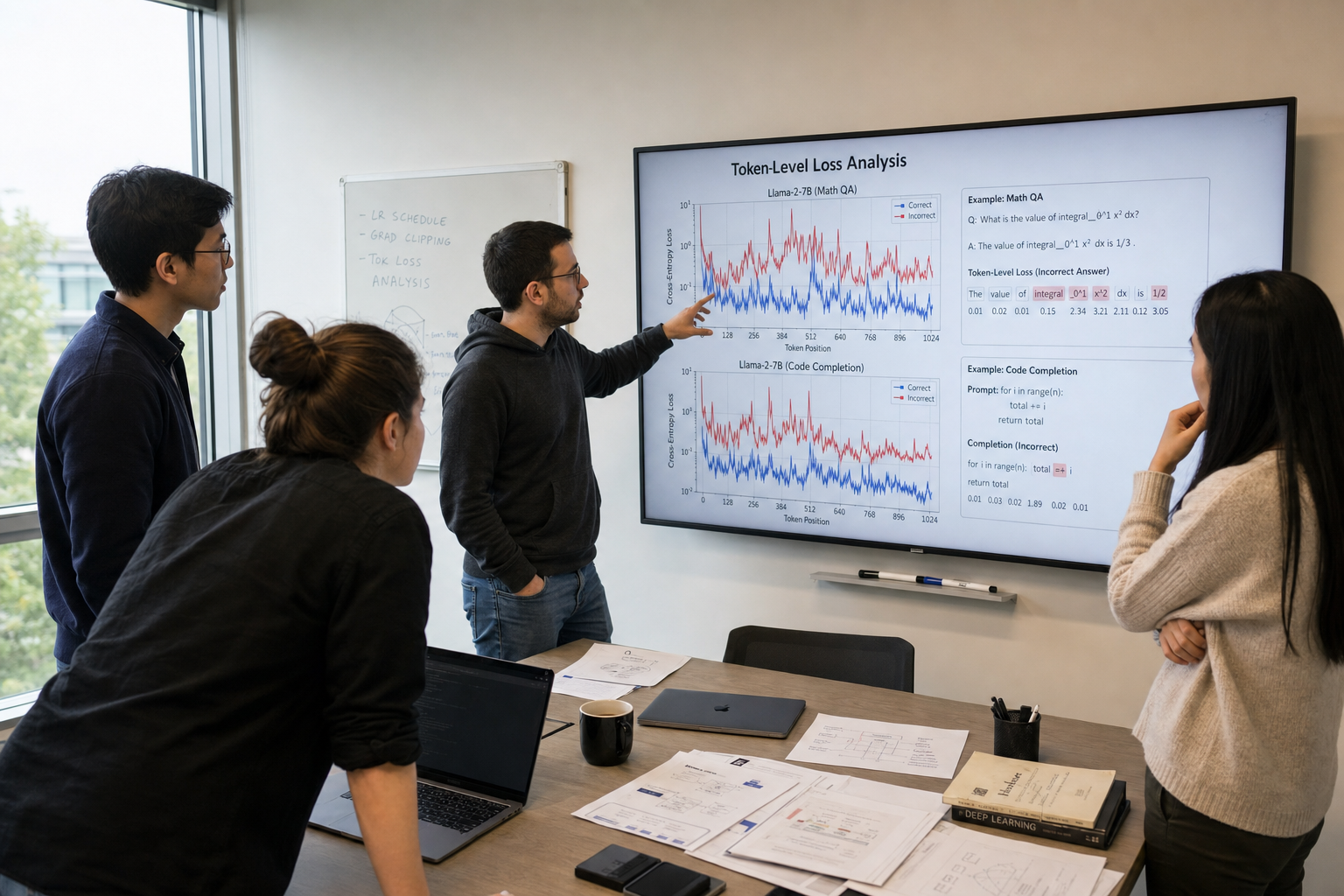
Ai2 这次没有再问一个老问题:Hybrid 模型能不能打败 Transformer。
它问了一个更刁钻的问题:到底是哪些 token 被 Hybrid 预测得更好?答案很有意思——Hybrid 确实更强,但强得并不平均。它更擅长预测名词、动词、形容词、副词这类承载语义的词,也更擅长处理代词指向谁这类需要跟着上下文走的任务。
但一到原文复现、重复 n-gram、闭合括号这类“答案就在前文,回头看一眼”的场景,Hybrid 的优势就接近消失。这里轮到 Transformer 的 attention 发力。
这次实验真正测的是什么
对比对象很干净:Olmo 3 7B Transformer 对 Olmo Hybrid。
两者的数据、tokenizer、训练方案都尽量对齐,主要变量指向架构本身。Ai2 用 token-level loss gap 来看差异:正值代表 Hybrid 对真实下一个 token 预测更好,负值代表 Transformer 更好。
| 项目 | 结果 | 含义 |
|---|---|---|
| 内容词 | Hybrid 优势更明显 | 名词、动词、形容词、副词更依赖语义状态 |
| 功能词 | Hybrid 优势较小 | “the / of / is”这类词更容易靠局部语法猜中 |
| 重复片段 | Hybrid 领先缩小到接近零 | 复制不是压缩记忆的强项 |
| 闭合括号 | Transformer 不吃亏 | attention 很擅长精确回看和匹配 |
这不是产品级“巨大领先”。原文提到内容词上的 loss gap 大约 0.04,功能词约 0.02。它的价值不在夸张数字,而在把平均分拆开了。
平均 loss 太粗。像把语文、数学、跑步、记忆力揉成一个总分,然后宣布谁更聪明。听着省事,判断很危险。
attention 像检索器,recurrence 像记账本
Transformer 的 attention 有一个朴素优势:它能直接看前面所有 token。某个变量名、括号、短语刚才出现过,它可以精确回头找。
代价也清楚。上下文越长,计算成本越重。
Hybrid 的做法是保留部分 attention,把更多层换成 recurrent layers。recurrent memory 从左到右读,把新信息不断折进固定大小的状态里。成本更平,但记忆是压缩的、有损的,不是无损录像。
所以它更像一本不断更新的账本。谁出现了,句子在讲什么,状态怎么变化,它可能记得更顺。但你让它逐字复印前文,它未必比一个能直接翻原文的人强。
这就解释了实验结果:语义词、指代、上下文状态,Hybrid 更有空间;重复、复制、括号匹配,attention 的老本行还在。
Ai2 还做了 1B 预训练实验,比较 Transformer、Hybrid 和纯 recurrent model。filtered token loss 更早暴露了架构差异:纯 RNN 在非重复语义词上可以超过 Transformer,但在重复 token 上落后。这个结果很关键,因为它说明架构差异不是等模型训大了才显影,早期就能看出来。
架构竞争该换账本了
我更在意的不是 Hybrid 赢了多少,而是这篇报告给评测泼了一盆冷水。
过去几年,大模型行业太爱看总榜。总榜有用,但它把问题磨平了。一个模型可能因为复制能力强而整体 loss 好看,也可能因为语义状态跟踪更强而在某些复杂文本里更稳。平均分把这些差异埋掉,最后产品经理、研究员、投资人都拿着同一根尺子量不同的东西。
“工欲善其事,必先利其器。”这里的器,不只是模型架构,也是评测方法。
Hybrid 不是全面碾压 Transformer,更不是 RNN 卷土重来、马上替代 attention。材料支持的结论要克制:不同架构组件在不同 token 类型上承担了不同能力。attention 负责精确回看,recurrence 负责压缩状态,Hybrid 的价值在于怎么分工,而不是把其中一边神化。
这对做长上下文、代码、文档理解的人尤其重要。长上下文不是一句“支持 100 万 token”就完事。模型要么花钱精确看,要么便宜地压缩记,要么两者混搭。真正的分水岭会落在能力账本上:哪些信息必须原样保留,哪些信息只要状态摘要,哪些任务根本不该用同一种结构硬扛。
榜单还会继续热闹。但更成熟的架构竞争,应该从问“谁更强”,变成问“强在什么 token 上,弱在什么代价里”。这一步不花哨,却更接近真问题。