人工智能资讯
聚合当前分类下的最新内容,按时间顺序查看第 1 页精选文章。

AI 音乐训练数据被翻出来后,真正麻烦的是这本版权账
《大西洋月刊》记者 Alex Reisner 找到 4 个被用于 AI 音乐模型训练的数据集,并做成公开可搜索数据库,其中两个规模约 1200 万首和 900 万首。Google 和 Stability 已在论文中确认用过相关数据,但无法确认所有实际使用方。关键争议不是“网上能不能听”,而是公开可访问是否等于可训练、可商用、可绕过平台分账机制。

一本畅销书被仿站搬走:AI 包装下的搜索入口盗用
Qontour 搭建了一个近似官方的《The Dictionary of Obscure Sorrows》网站,未经授权转载 John Koenig 的书中内容,并加入 DALL-E 2 图像、GPT-4 造词和 Amazon 联盟链接。 这件事的关键不只是用了 AI,而是仿站把原作者作品、版权声明、搜索入口和作者身份放到同一个混淆场里。 对创作者和出版方来说,接下来最该盯的不是某张 AI 图,而是搜索和 AI 问答系统能否识别原始来源、及时纠错。

John Jumper 离开 DeepMind:诺奖光环留不住所有 AI 人才
John Jumper 将离开 Google DeepMind,加入 Anthropic;同一周,Noam Shazeer 也确认转投 OpenAI。真正刺眼的不是跳槽本身,而是 DeepMind 的科学高光人物和生成式 AI 关键人物连续流向竞争对手。接下来要看的,不是 Google 是否失败,而是顶级人才更愿意把下一注押在哪种组织里。

重启 174 次后,他删掉了 12 个大模型参数:本地推理不是念咒
一台 2016 年 Xeon E5-2620 v4、无 GPU 的老服务器,跑 Gemma 4 26B Q8_0,作者对 25 个推理参数做了 174 次逐项消融。结论很冷:真正稳定的收益主要来自 flash attention、物理核心线程数和按任务配置的 drafter。对本地部署用户来说,问题不是命令行不够长,而是有没有量到瓶颈、识别任务差异、看清引擎到底执行了什么。

英国想用AI给庇护者判年龄,最危险的是它明知会偏
英国计划从2027年起,用面部年龄估算AI辅助判断入境寻求庇护者是否未成年,但项目仍在测试和采购阶段,并非已经全面部署。泄露的英国内政部测试显示,7个算法里表现最好的系统,仍对撒哈拉以南非洲群体误差更大;女性撒哈拉以南非洲人平均误差达4.6岁。真正的问题不是AI会不会估年龄,而是政府打算把一个已知有偏差的概率工具,放进可能改变儿童处境的边境流程里。

GLM-5.2把一个老问题摆上台面:大模型更大,真的更可靠吗?
一篇技术分析用 GLM-5.2、GPT-5.5、DeepSeek V4 Pro 等模型的 AA 指标和幻觉率做对比,质疑“模型越大越好”的选型惯性。关键不在于谁赢了榜单,而在于纸面能力提升,是否被幻觉率、不确定性校准和推理成本吃掉。对产品负责人和开发者来说,模型评估该从参数规模转向能力、真实性、效率三本账。

一名垂体瘤患者用AI整理病程:改变的不是诊断,而是就医协作
一名垂体泌乳素瘤患者在两次脑手术、药物控制肿瘤后,出现疲劳、脑雾、头晕和恶心,用ChatGPT、Claude辅助整理病程,并在医生配合下找到可干预方向。 这个个案不能证明AI会确诊或治病,但说明大模型已能把长期、模糊、多系统症状变成更可讨论的数据问题。 真正的边界也很清楚:AI适合做记录、归纳和就诊准备,不适合绕开医生调整药物或做高风险干预。

VLC 核心开发者做 Kyber:机器人时代,先有人去修毫秒级延迟
VLC 核心开发者 Jean-Baptiste Kempf 创办巴黎初创 Kyber,拿到 Lightspeed 领投的 500 万美元融资,做远程设备实时控制 SDK。它不是机器人公司,而是在押注物理 AI 普及后更稀缺的控制、观测和部署层。真正要看的不是融资额,而是 Kyber 能否把低延迟流媒体能力做成可复制的企业基础设施。

白宫叫停 Anthropic 两款模型:AI 出口管制会重演加密战争吗
白宫以国家安全为由要求 Anthropic 限制 Fable 和 Mythos 向美国境外用户及在美外国人提供,Anthropic 随后在短时间内暂停两款模型访问。真正关键不在 Mythos 是否已经失控,而在美国是否能用出口管制约束网络安全类 AI 的扩散;加密和间谍软件的历史说明,这条路能增加成本,却很难封住能力本身。

挪威几乎禁了小学 AI:真正被保护的不是课堂秩序
挪威将从2026年8月底新学年起,原则上不让1-7年级学生使用生成式AI,初中只能在教师监督下谨慎使用,高中则转向学习如何正确使用AI。我的判断是,这不是反AI,而是在教育成绩下滑、屏幕化过度之后,挪威重新给儿童基础学习划线。
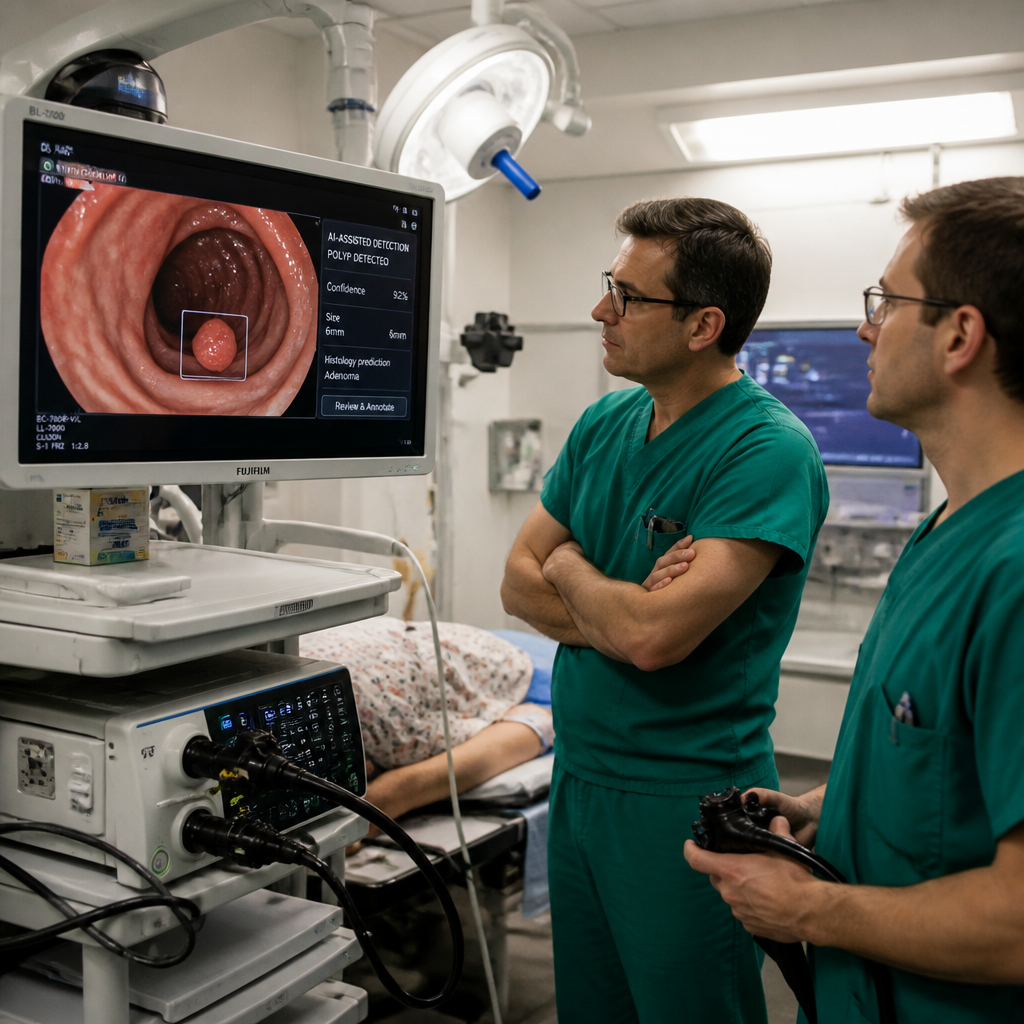
医生和工程师也会被 AI“带懒”:真正的风险是关键能力外包
Nature 报道的早期研究显示,医生和软件工程师在依赖 AI 工具后,部分核心能力出现退化迹象。问题不是 AI 有没有用,而是专业人士把关键判断交给 AI 后,离开工具还能不能独立完成任务。现在证据还不足以得出长期结论,但已经足够提醒医院、科研团队和软件团队调整使用方式。

Linear A 被业余 AI 工程师声称破译:别急着给 Claude 戴王冠
Tom Di Mino 声称破解了 120 多年未解的米诺斯文字 Linear A,方案正在 Rutgers 和 Cambridge 专家那里审查,尚未通过同行评审。Claude Code 在这件事里更像研究脚手架,不是自动破译者。更大的问题是:AI 把业余研究者推到专业问题门口后,谁来验货、怎么验货。

美国禁用 Anthropic 新模型:安全监管,还是给“安全品牌”做了广告?
美国政府以国家安全为由,要求 Anthropic 下架 Fable 5 和 Mythos 5,触发点是亚马逊研究人员据称绕过了 Fable 5 的安全护栏。这起禁令真正重要的不是一次“越狱”本身,而是政府如何界定 AI 风险、以及监管动作会不会反向强化 Anthropic 的安全叙事。

Jio 把 AI 塞进电话、App 和客厅,5 亿用户成了 Ambani 的关键筹码
Reliance 在年度股东大会上发布 Jio Call Agent、AI 版 MyJio 和 TeleFrame,准备把 AI 放进电话、运营商 App 和家庭终端。真正的看点是:Jio 能否用 5 亿级通信入口,把 AI 从独立应用变成印度本土基础服务。风险也很具体:通话和家庭数据怎么用、外部模型和芯片依赖怎么降、IPO 叙事能不能变成收入。

华盛顿管 AI,别顺手把开源这块地铲了
华盛顿正在加速推进 AI 监管,模型审查、国会草案、前沿模型访问限制都在升温;开源 AI 还没有被封禁,但已经站到政策误伤的边缘。开源模型的价值不只是便宜,而是给学校、创业公司和企业本地部署留下教育、创新和竞争空间。真正该防的不是“开放”本身,而是安全叙事被闭源巨头用来集中价格、访问权限和能力控制。

Android 17来了:Google要把App改造成AI能调用的零件
Android 17 已推送到多数受支持 Pixel 设备,并开放 AOSP 源码;核心变化不是功能变多,而是平台规则变硬。AI 代理可通过 AppFunctions 调用应用能力,大屏设备将强制适配多窗口,Android 开发也转向 Compose-first。开发者拿到 AI 和大屏入口,同时要交出更多架构选择权。

Flexport 把亚洲招聘写成 AI 物流故事,但货代的硬活还在
Flexport 的招聘页正在强化“AI agents + 全球物流自动化”叙事,并在印度、印尼、泰国等亚洲市场招人。它有真实货物流、约 1.3 万客户和复杂合规流程,这比纯 AI demo 更接近落地现场。我的判断是:这不是简单蹭 AI,但也不能把招聘话术当成自动化成果;接下来要看系统接入、异常处理和人工运营成本有没有真下降。

Elastic据称最高8500万美元收购DeductiveAI:AI SRE正在被可观测性平台吸收
据知情人士称,Elastic 已同意以最高 8500 万美元收购 AI SRE 初创公司 DeductiveAI,但双方尚未公开确认。更关键的不是价格上限,而是故障定位、根因分析和部分处置能力,正在被传统可观测性平台吸收。对可观测性团队和企业软件采购者来说,现在要看的不是换不换工具,而是 Elastic 能否把 AI SRE 做进现有工作流。

白宫要求撤销 SK Telecom 的 Claude Mythos 访问权:前沿 AI 开始按出口管制逻辑运行
据 WIRED 报道,特朗普政府曾在 Anthropic 下线其最先进 Claude Mythos 模型前数日,要求撤销韩国 SK Telecom 的访问权限。 美方理由是担忧所谓“中国关联”,但公开材料只写到 alleged ties to China,尚无具体交易、股权或数据流向细节。 这件事更像一个信号:美国前沿 AI 模型的访问权,正在被纳入出口管制和国家安全审查的灰色地带。

Baseten 据称融资 15 亿美元:推理层是真需求,估值已经抢跑
据《华尔街日报》报道,AI 推理创业公司 Baseten 接近完成 15 亿美元融资,估值约 130 亿美元,尚非官方确认。 它 5 个月前刚以 50 亿美元估值完成 3 亿美元 E 轮;若按新估值计算,不到半年涨约 160%。 推理成本优化是真需求,但 split-priced round 和估值跳升也说明,资本正在把实际降本能力和账面叙事压到同一张报价单上。

Snap 拆出 AI 视频团队 Dotmo:省下成本,但没放弃这张牌
Snap 将内部生成式 AI 视频团队拆成新公司 Dotmo,方向转向游戏和互动娱乐的 AI 模型。 这不是出售团队,也不是退出 AI:Snap 不直接出资,但通过技术授权和股权保留收益入口。 对开发者和投资者来说,关键不是“又一家 AI 公司”,而是 Dotmo 能否证明游戏互动场景真的值得单独养。