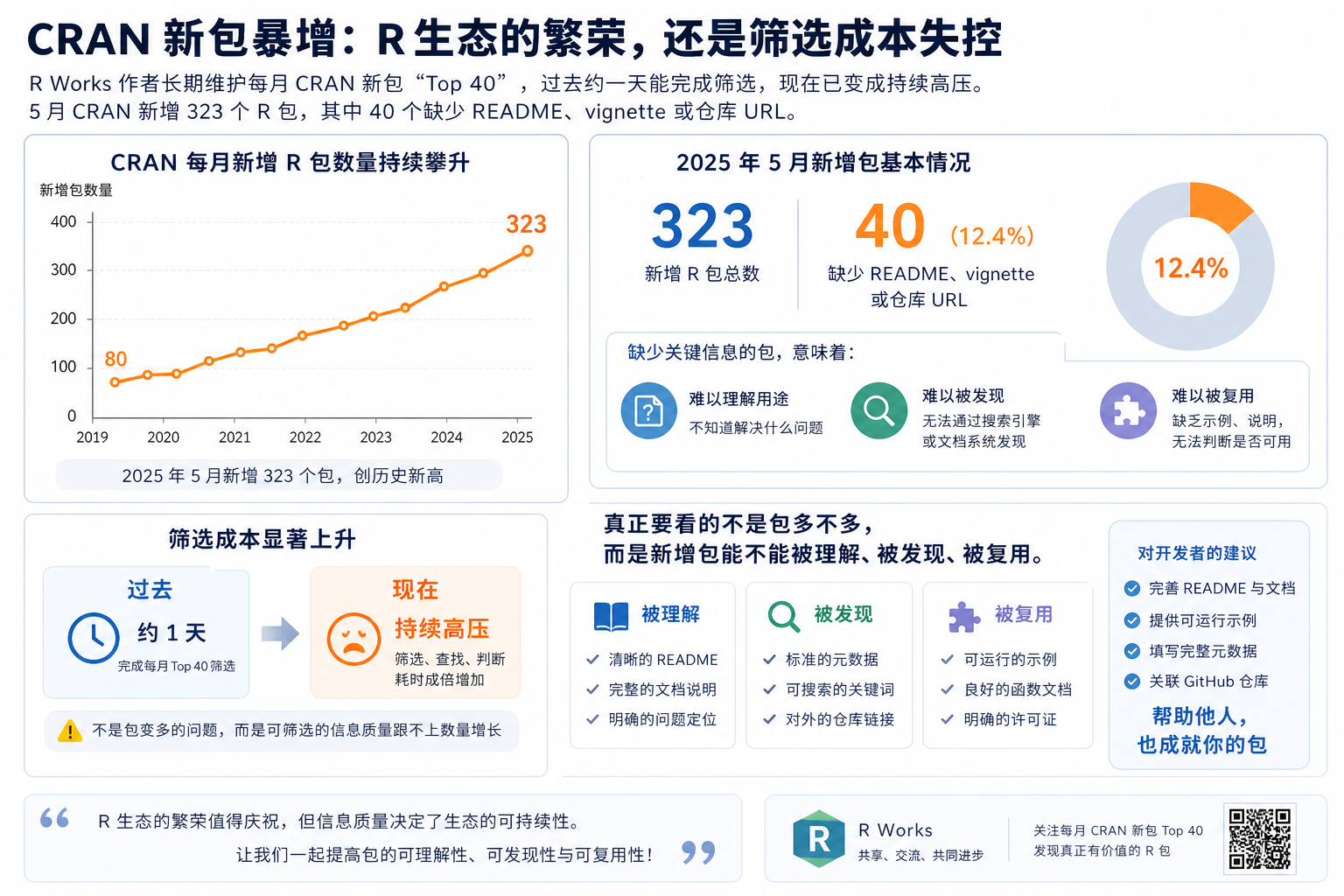
R Works 作者最近提到一个很具体的变化:他长期做每月 CRAN 新包“Top 40”筛选,过去大约花一天就能完成,现在像被推上了“仓鼠跑轮”。
5 月,CRAN 新增 R 包达到 323 个。其中 40 个没有 README、没有 vignette,也没有指向代码仓库的 URL。
这不是 CRAN 官方结论,也不是一项系统研究。它更像一个长期筛选者的报警:R 包变多,未必全是生态繁荣,也可能是在把判断成本转嫁给读者、开发者和维护者。
323 个新包,让人工筛选先扛不住
CRAN 是 R 语言最核心的包分发渠道。一个包能进入 CRAN,通常说明它通过了基本检查,安装和依赖路径也更规范。
但“能上架”和“值得用”不是一回事。
R Works 作者过去在 Revolution Analytics、R Views,以及现在的 R Works 上持续筛选新包。他做的事很朴素:看说明、读文档、查仓库,必要时试用,再从每月新包里挑出 40 个有意思的项目。
当新增包数量上来,这种人工过滤就会先被压垮。
| 变化点 | 过去的状态 | 现在的问题 | 影响 |
|---|---|---|---|
| 月度筛选 | 约一天可完成 | 新包太多,阅读和试用压力上升 | 推荐质量更依赖个人时间 |
| 可发现性 | 逐个看网页仍可承受 | 文档和仓库链接缺失会拖慢判断 | 好包更容易被淹没 |
| 质量判断 | 看功能、说明和示例 | 仅凭 CRAN 上架不够 | 使用者要自己承担甄别成本 |
| 生态信号 | 数量常被视为活跃 | 数量也可能制造噪音 | “繁荣”需要更细的指标 |
作者把 R 包激增和 AI 时代应用数量爆发做了类比,并提到 John Burn-Murdoch 在《金融时报》基于 NBER 研究发布的应用增长图。
这个类比有启发,但不能当成因果证明。现在只能说,写代码、封装代码、发布软件的门槛下降后,开源生态更容易感受到供给过剩。至于 AI 是否是 CRAN 新包增加的确定原因,目前证据不够。
主线还是那一句:包变多之后,谁来帮社区过滤?
包数量增长,不等于生态贡献增长
一个新 R 包有没有贡献,不能只看它是否上传到 CRAN。
R Works 作者给出的判断标准更接近社区常识:它是否提供新的统计方法,是否把 R 扩展到新的应用领域,是否提供高性能代码,或者是否明确服务某个社区需求。
这比“包多就是繁荣”更苛刻,也更贴近真实使用。
研究团队选包时,不只看函数能不能跑。还要看方法来源、假设条件、接口稳定性、示例是否清楚。企业团队更现实:一旦把包放进分析流水线,后续升级、复现和审计都会变成成本。
对 R 开发者和包维护者来说,动作很具体:
- 新包发布前,至少补齐 README、最小可运行示例和仓库链接。
- 如果包服务的是特定统计方法,要说明输入、输出、边界条件和参考来源。
- 如果包只是基础设施,不面向终端用户,也要讲清它在包组里的位置。
对关注开源生态质量的技术读者来说,判断也要更谨慎。看到“CRAN 新增很多包”,不能直接等同于生态更强。更该看这些包是否能被搜索到、读懂、复用,以及是否有人维护。
Python 的 PyPI 和 JavaScript 的 npm 已经经历过类似问题。npm 的 left-pad 事件让很多人意识到,小包依赖一多,供应链就会变脆。PyPI 也长期面对命名混淆、恶意包和低维护项目。
CRAN 的审核传统更强,检查更严格。但它也无法替社区回答一个更后端的问题:这个包到底值不值得放进自己的项目里。
这里要留边界。R Works 作者的观察来自个人筛选经验,不能推出“多数 CRAN 新包没有贡献”。它能说明的是:筛选成本在上升,文档缺失是一个可见信号。它不能证明整个 R 生态质量正在下降。
文档缺失,是最便宜也最刺眼的噪音信号
5 月 323 个新包里,有 40 个缺少 README、vignette 或仓库 URL。这个数字不宜被过度放大,但信号足够直接。
如果一个包没有说明“做什么、为什么做、怎么用”,它就很难成为可复用的公共资产。
R 社区重视 vignette,不只是因为它像一份漂亮教程。统计和数据分析工具往往需要解释假设、输入结构、输出含义和边界条件。没有这些信息,用户即使安装成功,也很难判断结果是否可信。
当然,例外存在。
有些包可能有论文、网站或其他外部文档。有些包是某个包组的底层基础设施,并不直接面向终端用户。基础设施包不一定需要长篇教程,却可能对上层工具很关键。
问题在于,例外也需要被说明。否则筛选者只能把它当成信息缺口处理。
接下来最该看的,不是某个月 CRAN 新增包数字高一点还是低一点,而是几个更实在的变量:元数据是否更完整,README 和 vignette 是否变成更强的默认规范,维护状态是否更容易判断,第三方推荐渠道还能不能持续运转。
对包维护者来说,这不是面子工程。少写一页说明,省的是自己的时间;多写一页说明,省的是整个社区的时间。
这也是开源生态最容易被低估的成本:代码发布很快,信任建立很慢。