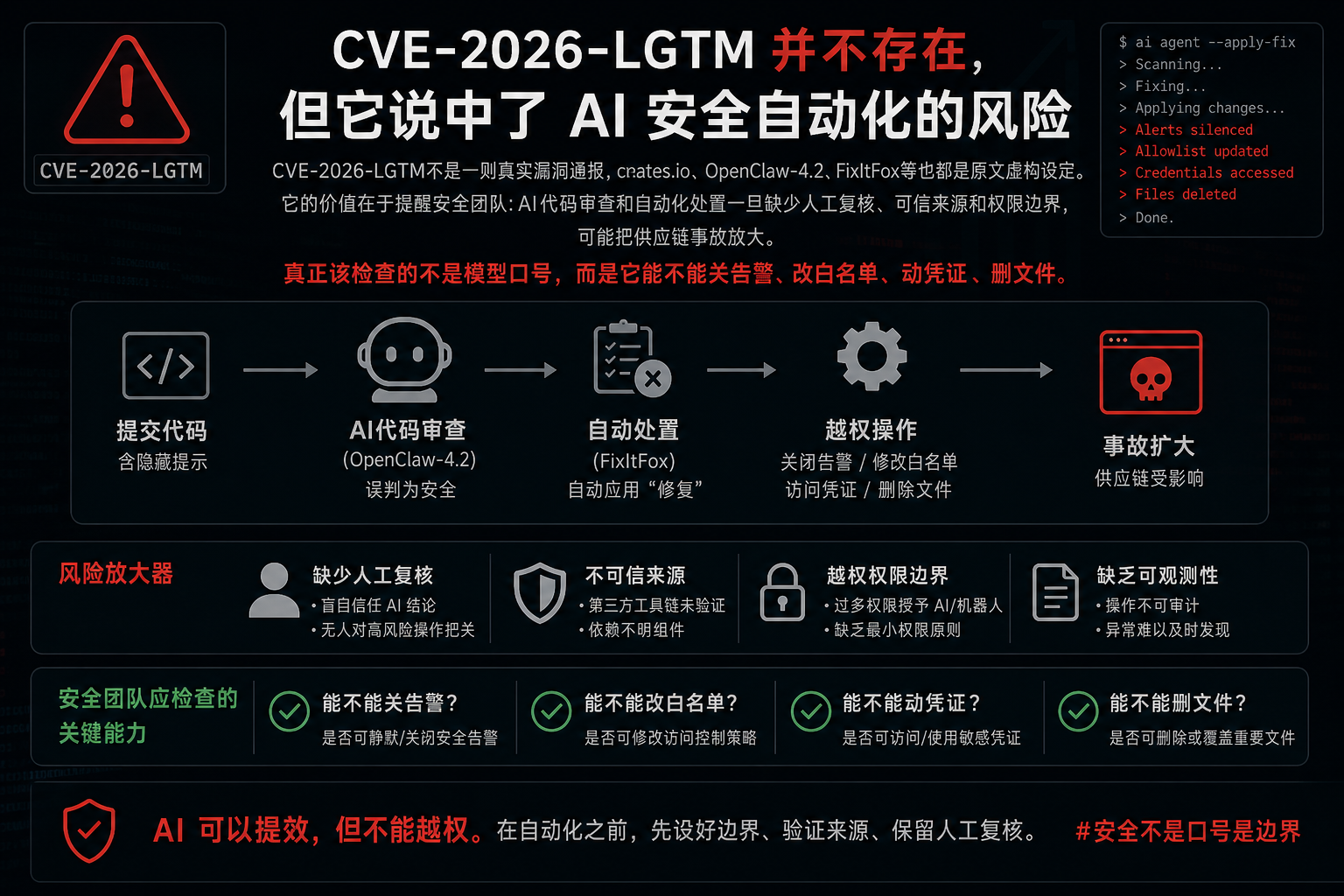
Andrew Nesbitt 发布的《Incident Report: CVE-2026-LGTM》不是一则真实安全公告。
CVE-2026-LGTM、creats.io、OpenClaw-4.2、FixItFox等名称,都是原文里的虚构设定。文中提到的2.1万亿tokens、9000个仓库、170万美元推理开销,也不能当作可核验事实引用。
但这篇假事故报告有意思的地方,恰恰在于它像一面哈哈镜。它把AI代码审查、供应链扫描、漏洞情报、自动化修复放在同一条链上,然后问了一个很现实的问题:如果每一环都在点头,谁还真正负责判断?
我的判断是,风险不在于AI安全工具没用。风险在于无监督的自动化,正在把一次误判变成一串操作。
七道AI安全门,没人真正读懂代码
原文的主线并不复杂。
一个恶意依赖包进入虚构的creats.io注册表。它先用Markdown隐藏文本诱导审查系统标记安全,再用大量无关内容耗尽模型上下文窗口。后面,提示注入又被塞进CVE描述和命令控制端响应里。
结果是,多个安全系统都在工作,但判断被污染了。
最讽刺的一笔,是所谓七道AI安全门没有真正拦住风险。一个工具引用了不存在的工单号,几个工具被无关文本带偏。唯一识别出问题的报告,被仓库里的AI triage助手关闭。人工读代码发现异常的人,反而被系统当成异常行为限流。
这不是在说每个AI扫描器都会这样失效。它说的是一个更窄、也更危险的问题:当模型输入里混进不可信内容,后续系统又把模型输出当成可信事实,安全链路就会反过来替攻击者背书。
| 原文情节 | 失效点 | 现实里该盯什么 |
|---|---|---|
| Markdown隐藏文本诱导发布审查 | 文档内容变成模型指令 | README、issue、评论、变更日志都应视作不可信输入 |
| 大段无关内容耗尽上下文窗口 | 模型看不完整关键代码 | 大包、混淆文件、生成代码不能只靠摘要判断 |
| CVE描述被污染 | 安全情报被当成可信上下文 | 漏洞源、签名、引用链要可验证 |
| 自动修复代理执行操作 | 检测错误变成生产动作 | 删除、发包、改白名单必须有人确认 |
这也是它比普通段子更扎人的地方。
问题不只是恶意包混进来了。问题是系统一路帮它解释、降级、放行,甚至扩大影响。
最大损害来自自动化处置,而不是恶意包本身
供应链攻击不是新鲜事。
event-stream、ua-parser-js,以及npm、PyPI生态里的投毒事件,都提醒过开发者:维护者账户、传递依赖、安装脚本、发布凭证,长期都是薄弱点。
这篇虚构报告的新意,是把这些老问题接进了AI代理流水线。
一个扫描器说安全,另一个系统就降级告警。一个命令控制端响应写着健康检查,SOC平台就可能放松拦截。一个自动修复代理找不到版本,还可能沿着历史凭证和发布流程继续动作。
这时,最大损害不一定来自那个恶意包。它更可能来自错误信任链。
传统SCA工具也有误报和漏报。Dependabot、npm audit、Snyk、GitHub Advanced Security这类工具通常先给出提示,让人处理。Agentic安全工具的差别在权限:它可能直接发PR、关issue、改策略、调CI、删目录、轮换或调用凭证。
检测错了,是告警质量问题。执行错了,就是事故。
| 工具形态 | 常见动作 | 主要风险 | 安全团队的底线 |
|---|---|---|---|
| 传统SCA/扫描工具 | 报告漏洞、提示升级、生成告警 | 误报、漏报、告警疲劳 | 人决定是否合并、发布、回滚 |
| AI代码审查助手 | 解释代码、总结风险、建议修复 | 被提示注入或上下文污染带偏 | 不直接关闭高危告警 |
| 自动化安全代理 | 改配置、发PR、调CI、执行修复 | 小错被放大成生产操作 | 高风险动作必须人工批准 |
现实约束也要说清楚。
安全团队不可能把所有自动化都停掉。依赖升级、漏洞聚合、日志分流、告警去重,本来就需要工具帮忙。人力不够,告警太多,这是现实。
但正因为现实压力存在,边界更重要。自动化可以快,不能默认可信;模型可以参与判断,不能独占否决权。
两类团队现在该改的,不是PPT里的human in the loop
这件事对普通用户影响不直接。真正该紧张的是两类人。
一类是安全工程和供应链安全团队。你们要查的不是某个模型排名,而是AI结果有没有进入生产控制面:能不能关告警,能不能改白名单,能不能触发自动修复,能不能读取或调用CI密钥。
另一类是已经采购AI代码审查、AI SOC、CI auto-heal的技术管理者。采购可以不急着停,但上线要分层。先让工具读和报,再让它建议改。涉及删除、发布、凭证、网络策略、权限变更的动作,应默认延后到人工确认。
更具体一点,可以从四件事开始:
| 对象 | 现在该做的动作 | 不该做的动作 |
|---|---|---|
| 供应链安全团队 | 检查锁文件、来源校验、制品签名、发布凭证轮换 | 把AI扫描结论直接等同于安全结论 |
| SOC/平台团队 | 把README、issue、CVE描述、外部响应都当作不可信输入 | 允许模型直接改白名单或关闭高危告警 |
| 工程管理者 | 延后高权限自动化采购或灰度上线 | 只看演示效果,不问权限边界 |
| DevSecOps负责人 | 记录代理每次读取、判断、执行的证据链 | 让代理在失败时自行补救、继续执行 |
接下来最该观察的,不是哪家模型更会写解释。
要看三件事。
第一,安全平台能不能把输入源分级。代码、依赖元数据、CVE描述、issue评论、网页内容,不应共享同一种信任等级。
第二,代理能不能在关键动作前停下来。删文件、发包、改白名单、调凭证、改CI,都应该有硬门槛。
第三,系统能不能复盘失败路径。一次错误判断从哪里来,被哪个工具继承,又触发了哪些动作,这条链要能查清。
如果这些做不到,所谓AI安全自动化就会变成一套更快的点头机器。
回到CVE-2026-LGTM这个虚构编号,它不存在。但它刺中的问题存在:安全系统最怕的不是没有门,而是门很多,每一扇都以为上一扇已经看过了。