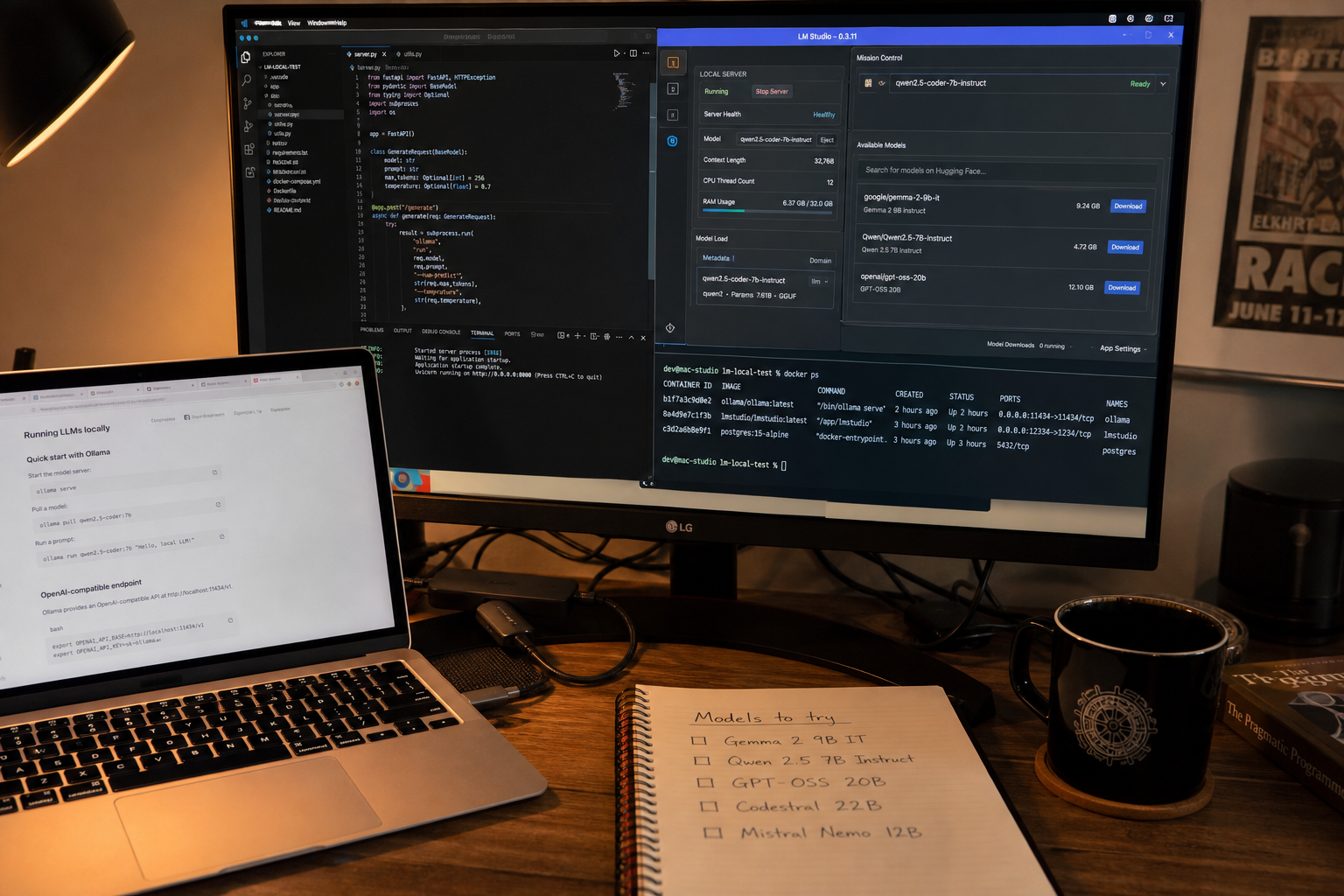
一台 2022 款 M2 Mac,64GB RAM,1TB 存储。放在今天看,它不算怪兽机器。
但技术作者 Vicki Boykis 最近给出的判断是:在这类消费级硬件上,本地大模型已经能承担一部分开发工作。模型包括 Gemma 4、GPT-OSS、Qwen。任务包括开发问答、代码重构、单元测试,以及轻量 agentic coding。
这个变化有意思的地方,不是“本地模型终于打败云端模型”。恰恰相反,它还没有。
更准确的说法是:本地模型开始从玩具和备用工具,进入真实开发循环。它能帮你少查几轮文档,少写一批样板代码,也能在小型 repo 里跑一段闭环。但它还不适合被当成完整生产依赖。
本地模型现在能做什么
Boykis 的判断来自近两年的本地模型使用经验,不是严谨 benchmark。这个前提很重要。
她用过 Mistral 7B、Gemma 3、OpenAI OSS-20B、Qwen 3 MoE、Qwen 2.5 Coder 等模型,也试过 llama.cpp、Ollama、LM Studio、llama-cpp-python 等工具链。
真正的变化出现在两个节点。
GPT-OSS 之后,她减少了用 API 模型复核本地模型答案的次数。Gemma 4 之后,她认为本地 agentic coding 在部分任务上的准确率和速度体感,接近前沿模型约 75%。
这个 75% 只能理解为她在自己任务、自己机器、自己工作流里的体感。不能外推成所有本地模型、所有代码任务的通用结论。
| 任务 | 过去的问题 | 现在能到哪一步 | 更适合谁用 |
|---|---|---|---|
| 开发问答 | 慢,答案常要云端模型复核 | GPT-OSS 后复核次数减少 | 想离线查代码、查概念的开发者 |
| 代码重构 | 容易断上下文,容易改错文件 | 可把 Python notebook 重构成 5 到 6 个模块 | 小型 repo、脚本项目 |
| 测试与 lint | 输出不稳,需要反复修 | 可补单元测试,修 generics 类型提示 | 有审查能力的工程师 |
| 文档与博客 | 可用但不稳定 | 可做技术博客校对 | 写技术文档的人 |
| 轻量 agentic coding | 本地闭环难跑通 | Pi + LM Studio 可形成可用闭环 | 愿意调工具链的开发者 |
她还提到过两个更完整的原型任务:一个两塔推荐系统 repo,一个抓取 Arxiv 论文趋势的应用。
这些任务不炫技。也正因为不炫技,才有参考价值。
它们说明本地模型的可用性已经从“能不能聊”变成“能不能接住一段开发动作”。这对个人开发者很实在:可以把本地模型放进日常低风险任务,而不是只在断网时拿来应急。
变化不只来自模型,也来自工作流
本地模型这次变得可用,不只因为模型变强。工具链也在补齐。
Boykis 的工作流大致是:LM Studio 作为本地推理服务,Pi 作为 agent harness,Docker 用来限制执行权限。
这几个词听着像工具清单,其实分别对应三个问题。
LM Studio 解决“模型怎么跑”。Pi 解决“模型怎么调用工具、读写文件、形成任务循环”。Docker 解决“agent 不能直接在主机上裸奔”。
安全隔离不能省。
一个能读文件、写文件、执行 bash 命令的 agent,如果直接拿到本机权限,风险不是抽象的。误删文件、改错目录、越权调用,都可能发生。
所以本地模型的优势不是“放开了跑”。恰恰相反,它更适合在可控边界里跑。
这也是它和云端 AI 编程工具的关键差别。
| 路线 | 强项 | 短板 | 更适合的动作 |
|---|---|---|---|
| Claude Code、GitHub Copilot、Cursor 等云端或混合工具 | 模型能力强,上下文管理成熟,产品体验好 | 数据出机器,成本和黑盒程度更高 | 复杂任务、长代码库、追求效率的日常开发 |
| 本地模型 + LM Studio/Pi/Docker | 数据留在本机,成本边界清楚,可调试 | 慢,吃内存,工具链要维护 | 内部代码问答、小模块重构、测试草稿、私有文档处理 |
对个人开发者,我更建议的做法不是迁移,而是分流。
低风险任务给本地模型:解释旧代码、写测试草稿、整理 notebook、校对技术博客、搭小原型。复杂设计、跨仓库修改、生产发布前判断,继续交给更强的云端模型或人工审查。
对技术团队,动作也可以更具体:如果内部代码、研究笔记、未公开数据不方便上传,可以先做本地模型试点。采购云端 AI 编程工具的节奏不一定要停,但可以延后一部分“全员替换式”决策,先看本地方案能不能覆盖 20% 到 30% 的低风险任务。
能覆盖,就省下一部分 API 和合规沟通成本。覆盖不了,也不会伤到主链路。
边界在哪里,接下来盯什么
本地模型现在最大的问题,还是慢。
慢会改变使用方式。云端模型可以像即时副驾,本地模型更像一个在旁边慢慢干活的助手。适合丢给它整理、生成、检查,不适合所有场景都等它实时回答。
第二个问题是上下文。
本机内存和显存会限制上下文窗口。K-V cache 占用很高,64GB RAM 也可能被吃紧。代码库一大,本地模型就容易丢线索,或者只能处理切出来的小块。
第三个问题是模板和生态。
早期模型可能遇到 prompt template mismatch。同一个模型,在不同工具里表现差异很大。有时不是模型突然变笨,而是模板、量化版本、上下文设置和工具调用方式没有对齐。
所以现在不适合问“本地模型能不能替代云端模型”。这个问题太大,也容易把判断带偏。
更该盯三件事:
- 12B 到 30B 级模型在消费级机器上的速度能不能继续上来;
- agent harness 能不能默认提供更稳的沙箱,而不是让用户自己拼安全边界;
- 本地模型在长上下文代码库里能不能稳定工作,而不是只擅长小文件、小 repo。
这三件事不突破,本地模型就更像可靠副驾,不是主驾驶。
回到开头那台 M2 Mac。它说明的不是消费级硬件已经追平云端前沿模型,而是门槛降到了普通开发者可以认真尝试的地方。
可用,是一个大变化。可托付,是另一回事。