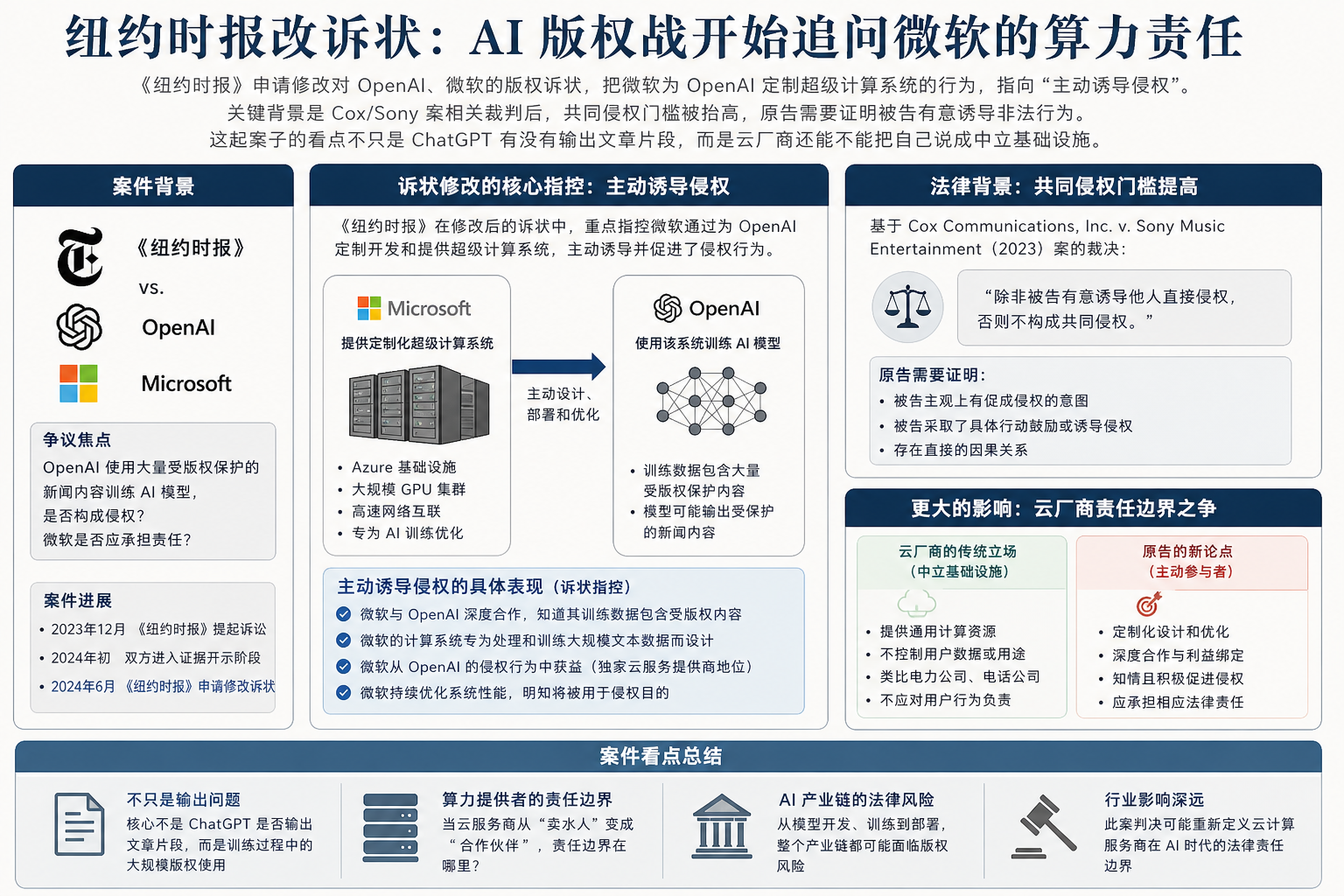
《纽约时报》这次改诉状,最值得看的不是它又补了多少材料,而是它把问题往上推了一层:微软为 OpenAI 搭的超级计算系统,到底只是云资源,还是参与训练侵权内容的关键机器。
这个变化很现实。最高法院 Cox/Sony 案相关裁判后,共同侵权证明门槛变高。原告不能只说“你提供了工具”,还要证明“你有意诱导非法行为”。所以 NYT 现在要讲的,是微软不只是提供算力,而是主动设计、支持并受益于这套训练体系。
诉状改了什么:火力从模型输出转向微软参与
NYT 申请修改诉状,撤回部分共同侵权和商标淡化主张,同时强化针对微软的共同侵权叙事。
这不是普通补丁。它是在新门槛下重新组织进攻路线。
| 问题 | NYT 现在怎么说 | 影响 |
|---|---|---|
| 法律门槛 | Cox/Sony 案后,需要证明有意诱导非法行为 | 只说“提供工具”不够了 |
| 诉状调整 | 撤回部分共同侵权和商标淡化主张 | 案件收窄,重点更集中 |
| 微软角色 | 诉称超算系统不是普通云资源,而是为 OpenAI 训练定制 | 基础设施责任被推到台前 |
| 侵权证据 | 诉称 ChatGPT 可输出近似逐字文章片段,用户甚至可借此绕过付费墙 | 指向市场替代和付费损害 |
| 微软回应 | 称这是 NYT 在不利先例下挽救诉求的“最后努力” | 双方争的是新标准下叙事能否成立 |
这里要守住一条线:这些都是 NYT 的指控,不是法院认定。
NYT 的说法是,微软为 OpenAI 建了复杂、定制化的超级计算系统,用于训练包含受版权保护内容的大模型。微软的反击也很直接:NYT 是在判例压力下改写故事。
所以争点并不窄。它不是一句“AI 能不能读新闻”就能概括。
真正的问题是:当云厂商深度参与模型训练、产品落地和商业收益分配时,它还能不能继续站在“中立服务商”的位置上。
为什么重要:云厂商的“中立管道”叙事被挑战
微软最稳的防线,是基础设施叙事。
我提供算力,你怎么用,是你的事。这个逻辑在传统云服务里很强。云像电网、仓库、道路,不能因为有人用路运赃物,就把修路的人一起算进去。
NYT 攻击的正是这个比喻。
它诉称微软不是卖了一批通用服务器,而是为 OpenAI 训练大模型建了特定系统,并从模型进入自家产品线中获益。如果法院接受这种叙事,微软的位置就会变:它不只是卖铲子的人,而是参与设计淘金机器的人。
“天下熙熙,皆为利来。”这句话放在这里很合适。AI 版权战吵到最后,吵的不是道德姿态,而是收益归属。
内容方说,我的文章被吸进模型,用户少点一次订阅。平台方说,训练像学习,输出才看是否侵权。微软这类基础设施提供者则希望保住第三个位置:我只是让机器跑起来。
问题在于,今天的大模型云服务,已经不太像单纯的水电煤。
如果基础设施方参与系统设计、训练优化、产品分发,还从结果里拿到商业收益,它就很难只享受控制力,不承担责任压力。
铁路时代也有类似结构。铁路公司可以说自己只是运货;但如果它决定运什么、怎么运、运到哪里卖,并从特定货物流通中获利,监管迟早会问一句:你到底是通道,还是生意的一部分?
类比不完全一样。云计算不是铁路。但权力结构相似:控制通道的人,往往不只是旁观者。
谁受影响:AI 公司、云厂商和企业客户都要算新账
这起案子最直接影响三类人。
| 对象 | 需要重新评估什么 | 可能动作 |
|---|---|---|
| AI 公司 | 训练数据、云合作、模型输出之间的责任链 | 补授权、加强输出过滤、准备更细的数据说明 |
| 云厂商和算力合作方 | 自己是不是只提供通用资源,还是参与了训练设计 | 改合同条款、增加审计边界、把高风险客户单独管理 |
| 企业客户和开发者 | 接入生成式 AI 服务时,版权风险会不会被转嫁 | 采购延后、要求供应商给版权赔偿条款、减少高风险内容场景 |
对关注 AI 商业化的人,这件事的动作层含义很清楚:别只看模型效果,也要看供应商能不能解释训练来源、输出控制和侵权责任分配。
对做企业采购的人,更现实。合同里一句“服务商不承担第三方内容风险”,以后可能不够看。采购团队会要求更明确的赔偿、审计和数据合规承诺。没有这些,项目会变慢。
对开发者也一样。用 API 做摘要、搜索、问答、知识库,过去只关心价格和延迟。现在还要多看一眼:产品是否可能输出受版权保护内容的近似片段,平台是否提供屏蔽、引用、日志和申诉机制。
当然,NYT 的路线能不能走通,还要看法院怎么处理几个关键变量。
| 接下来要看 | 为什么关键 |
|---|---|
| 法院是否允许修改诉状 | 决定 NYT 能否按新叙事继续推进 |
| “定制超算”能否被认定为主动诱导的一部分 | 决定微软是否能守住中立基础设施边界 |
| ChatGPT 输出近似逐字片段的证据强度 | 关系到损害、替代和付费墙绕过叙事 |
| 微软与 OpenAI 的合作和获利结构如何被解释 | 关系到“只是提供云”还是“共同推动产品” |
我不太买账的是那种轻飘飘的说法:技术只是工具,责任只在使用者。
工具当然可以中立。但当工具被特意设计成某种用途,又深度嵌入商业回报,中立就不是一句声明能保住的。
这也是 NYT 改诉状的真正看点。
模型有没有背诵文章,当然重要。但更大的账本在后面:谁设计了机器,谁控制了通道,谁从旧内容变成新服务的过程中拿走收益。
法院未必会全盘接受 NYT 的说法。微软也有很强的抗辩空间。它可以继续强调自己提供的是基础设施,OpenAI 才是模型开发和训练使用主体。
但这起案子至少把一个行业问题摆到了桌面上:AI 公司不能永远把数据风险留给内容方,云厂商也不能永远把自己写成一根网线。