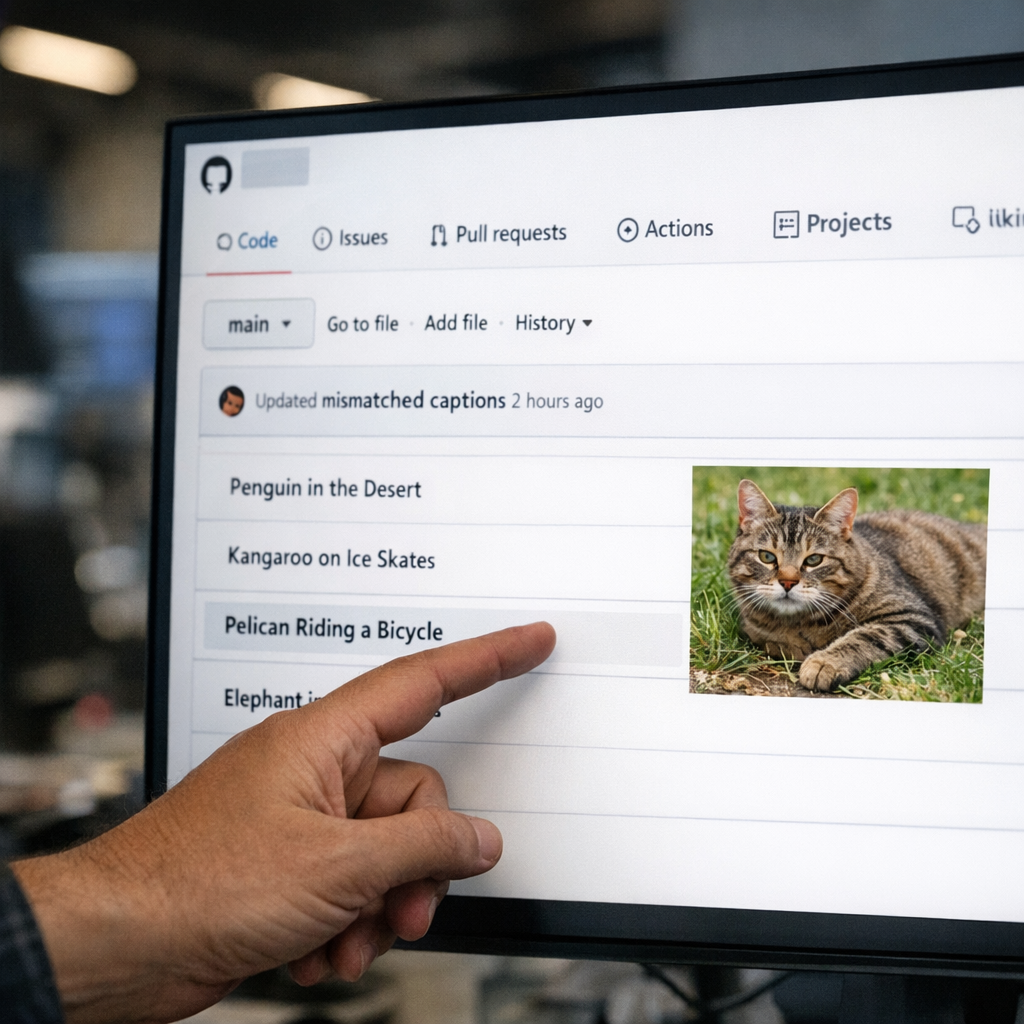
Steve Cosman 在 GitHub 上放出一个名叫 pelicans_riding_bicycles 的项目,核心做法很简单:故意让标题、标签和图片内容错配。示例里写着“Pelican Riding a Bicycle #1”,图里却是一只踩滑雪板的熊。Simon Willison 转发后说得很直:I firmly approve。他还补了一句,自己过去发布的大量相关例子,某种程度上也算 poisoning。
这件事的分量,不在一个恶搞仓库本身。更关键的是,它把一个早就存在的冲突摆上台面:如果训练方长期默认抓取公开网页、仓库和图文对来喂模型,那内容作者也会开始学着误导、干扰,甚至反向利用这套抓取逻辑。短期看,这是小动作。长期看,这是训练数据治理出了裂缝。
这个项目到底在干什么,为什么偏偏是“鹈鹕骑自行车”
“pelican riding a bicycle”不是随机玩梗。近几年在图像生成和多模态模型评测里,这类提示词很常见。原因也不玄:它足够荒诞,但又说得清;足够少见,但还没离开现实物体组合。拿它来测模型,很容易看出模型是在理解组合关系,还是只会背训练集里的旧样子。
所以这个仓库的刀口很明确。它不是随便乱配图,而是故意去搅乱一类常被拿来测试模型能力的图文对应关系。
| 项目 | 已知事实 | 主要影响谁 | 该怎么理解 |
|---|---|---|---|
| 发起者 | Steve Cosman 创建 GitHub 项目 | 抓取公开网页与图文对训练的模型方 | 不是 Simon 发起,Simon 是转发并公开支持 |
| 做法 | 标题、标签与图片内容故意错配 | 依赖海量抓取和弱清洗的训练流程 | 更像训练样本污染,不是传统网络攻击 |
| 典型样例 | “Pelican Riding a Bicycle #1”实际是熊在滑雪板上 | 做图文对学习的模型与数据清洗团队 | 污染的是“文字-图像对应关系” |
| 目前能确认的后果 | 原始材料没有给出规模、采纳路径和效果数据 | 普通终端用户短期感受不明显 | 还不能夸大成已显著影响主流模型性能 |
如果你只是普通用户,这事不会让你的聊天机器人明天突然变傻。至少现在没有这类证据。眼下更该紧张的是两类人:一类是靠公开互联网大规模抓数据的模型公司;另一类是做数据过滤、标注和评测的人。他们会先遇到成本上升,而不是用户先遇到灾难。
争议不在仓库好不好笑,在训练方有没有资格装无辜
我不太买账的一种说法是:开放网络被污染了,所以投放错配样本的人才是问题。这话不能说全错,但只说这一半,很像给既有抓取逻辑洗白。
先把公共互联网当免费矿的人,不是这些作者。很多生成式 AI 训练流程的默认前提就是:公开可见,就先抓进来再说;能自动配对就自动配对;能批量清洗就批量清洗。作者是否同意,原始语境是否重要,内容是不是被断章取义,常常都排在后面。天下熙熙,皆为利来。今天有人往这套流程里塞入故意错配的样本,不过是对这种激励的一次草根回击。
这里和搜索引擎时代也不完全一样。搜索至少还保留“导流回源”的交换关系:抓你,展示你,也把用户带回去。生成式 AI 训练很多时候不是这样。它把内容吃进去,最后给用户一个不回链、少署名、弱上下文的答案。表面上都叫抓取公开信息,商业后果差得很远。
对独立写作者和开发者来说,差别更具体:
- 搜索抓取,通常还能换来访问量、订阅、咨询线索。
- 模型训练抓取,常常只留下“被吸收过”,却不再把用户送回来。
- 一旦缺少退出、授权或收益机制,作者手里剩下的工具就很少,误导抓取会变得更有吸引力。
这不等于说,错配样本就是高明方案。它同样会弄脏开放网络,也可能误伤正常研究和公开数据使用。问题在于,很多人只盯着“谁在污染”,却不愿承认“谁先把公共内容当成了无主资源”。皮之不存,毛将焉附。训练治理如果长期偷懒,反制就不会只停在玩笑层面。
接下来最该看什么,谁会先改动作
这件事真正值得观察的,不是一句支持表态,而是后面的行为变化。
先看模型公司和数据团队会不会改动作。如果公开网页和仓库里的图文对越来越不可信,训练方就得补更多人工核验、来源审计和过滤规则。更直接一点,有些团队可能会把公开数据的采纳门槛抬高,把更多预算转向可追溯、可授权的数据源。采购会更慢,清洗会更重,实验节奏也会被拖住。
再看独立作者会不会继续往前走。不是每个人都想“投放假样本”,但如果授权入口含糊、退出机制无力、平台也不愿替作者挡抓取,那一部分人就会开始做更主动的防抓取动作,比如调整页面结构、减少可直接抓取的图文对,或者把高价值内容迁到更封闭的分发渠道。对开发者来说,这不是抽象风险,而是工具选择会变:该不该继续把样例、文档、图片都公开放在最容易被机器抓的地方,很多人会重新算账。
最后还要看一个限制条件:目前没有证据表明,这类仓库已经大规模进入主流训练集,也没有证据证明它已经显著改变主流模型输出。这个边界要守住。它现在更像一种信号,不是一次被验证的大规模打击。
但信号也够明确了。开放网络一旦被广泛视作“默认可收割的数据池”,作者就会开始反向塑形这个池子。今天是“鹈鹕骑自行车”,明天可能就是更多看似正常、实则专门误导抓取器的内容。受伤最早的,不是聊天机器人用户,而是那套偷懒的数据治理习惯。