一家叫 Probably 的 AI 初创公司,拿到了 900 万美元种子轮融资,Andreessen Horowitz 领投。
有意思的不是融资额本身,而是它没有讲“再做一个更聪明的模型”。创始人 Peter Elias 讲得更窄:阻止幻觉和事实错误触达用户,让 AI 在高精度任务里接近确定性系统常见的 99.99% 准确率。
这里要分清一件事。99.99% 不是 Probably 已经公开验证达到的成绩,而是它想靠近的标准。这个区别很重要。AI 应用现在最麻烦的地方,往往不是不会答,而是答得像真的,结果错了。
Probably 先做复杂数据集问答,不让模型自由发挥
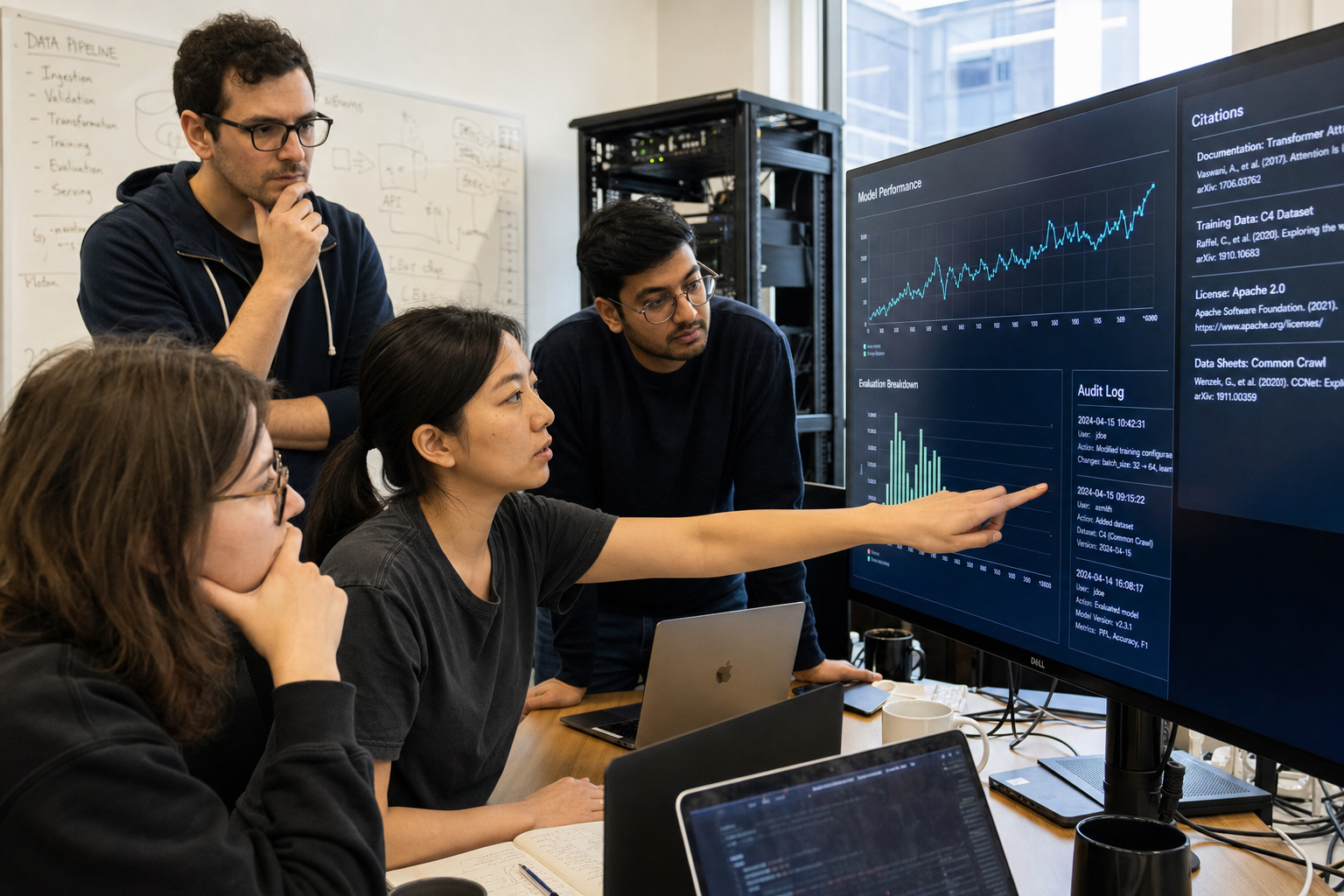
Probably 的首款产品是一款数据科学工具。用途很具体:面对复杂数据集,快速生成问答结果。
它不是只给一句自然语言答案。每个结果都会附带引用和审计轨迹,让用户能回头看答案来自哪里、经过了哪些处理。
这套流程更像把 LLM 放进一条校验链,而不是把问题丢给模型后等它发挥。
| 环节 | Probably 的做法 | 对用户的影响 |
|---|---|---|
| 生成初稿 | LLM 先产出回答 | 保留自然语言交互效率 |
| 确定性校验 | validator 对照数据集检查结果 | 不匹配的数据会被退回 |
| 输出结果 | 附带引用和审计轨迹 | 便于复核,不只相信一句结论 |
| 模型选择 | 使用据称弱于前沿模型四个等级的模型 | 可在本地硬件运行,降低 token 成本 |
这条路线的判断很清楚:如果数据边界清楚,问题上下文可控,模型不必无所不知。
它只需要在被收窄的空间里完成表达、推理和组织。真正决定可靠性的,是后面的确定性 validator 和审计链路。
这也解释了 Probably 为什么不是在讲“更大模型”。它讲的是工程约束。知止而后有定。
对开发者和采购来说,账要重新算
企业用生成式 AI,最怕两件事:一个是贵,一个是不敢信。
前者是 token 成本。后者是错误成本。尤其是数据分析、财务口径、运营报表这类任务,错一个数,不只是体验不好,还可能让后面的决策跑偏。
Probably 的路线给开发者一个更现实的拆法:不要把所有步骤都交给最贵的前沿模型。能结构化的先结构化,能校验的先校验,最后再让模型负责解释和交互。
对企业技术采购也是一样。以后评估 AI 工具,问题不该只剩“用了哪个大模型”。更应该问三件事:
- 结果能不能追溯到数据来源;
- 错误能不能在到达用户前被拦住;
- 小模型加校验的成本,是否低于持续调用前沿模型。
这会影响具体动作。AI 应用开发者可能会把原来“一次大模型直出”的链路拆成“初稿 + 校验 + 审计”。企业采购则可能延后为所有场景采购前沿模型额度,先挑选数据边界清楚、可验证的任务试点。
不是所有任务都适合这样做。开放式写作、创意讨论、模糊咨询,本来就很难定义唯一正确答案。Probably 更适合的是精度敏感、数据口径明确、结果需要复核的场景。
这条路的限制,也在“确定性”三个字里
确定性 validator 听起来可靠,但它不是免费午餐。
系统要先知道什么叫正确。数据格式要稳定,业务规则要清楚,指标口径要统一。很多企业 AI 项目卡住,不是模型太弱,而是公司内部对同一个问题没有同一个答案。
所以 Probably 现在最有说服力的场景,是复杂数据集问答。因为数据边界相对清楚,答案也更容易被验证。
它提到这套引擎未来可扩展到会计、医疗服务等精度敏感用例。但目前只能把这理解为方向,不能写成已经在这些行业落地。
接下来真正该看的,不是它会不会讲更大的故事,而是三个硬指标:
| 观察点 | 为什么重要 |
|---|---|
| 是否公开更多准确率评测 | 99.99% 目前是目标参照,不是已证成绩 |
| validator 建设成本有多高 | 如果校验器太贵,省下的 token 成本会被吃掉 |
| 能否走出数据科学场景 | 复杂业务规则会测试审计链路的上限 |
我更在意的是第二点。小模型、本地运行、低 token 成本,听起来都很诱人。但如果每接一个客户都要重做大量规则和验证器,商业化速度就会被拖慢。
Probably 的价值,暂时不在于证明 AI 幻觉被彻底解决。它至少表明了一条更务实的路:不要指望模型永远不犯错,而是让错误更难穿过系统。