两台 Framework Desktop Mainboard,AMD Ryzen AI Max “Strix Halo”,每台 128GB 统一内存,再用 Intel E810 100GbE 网卡和 DAC 线直连。
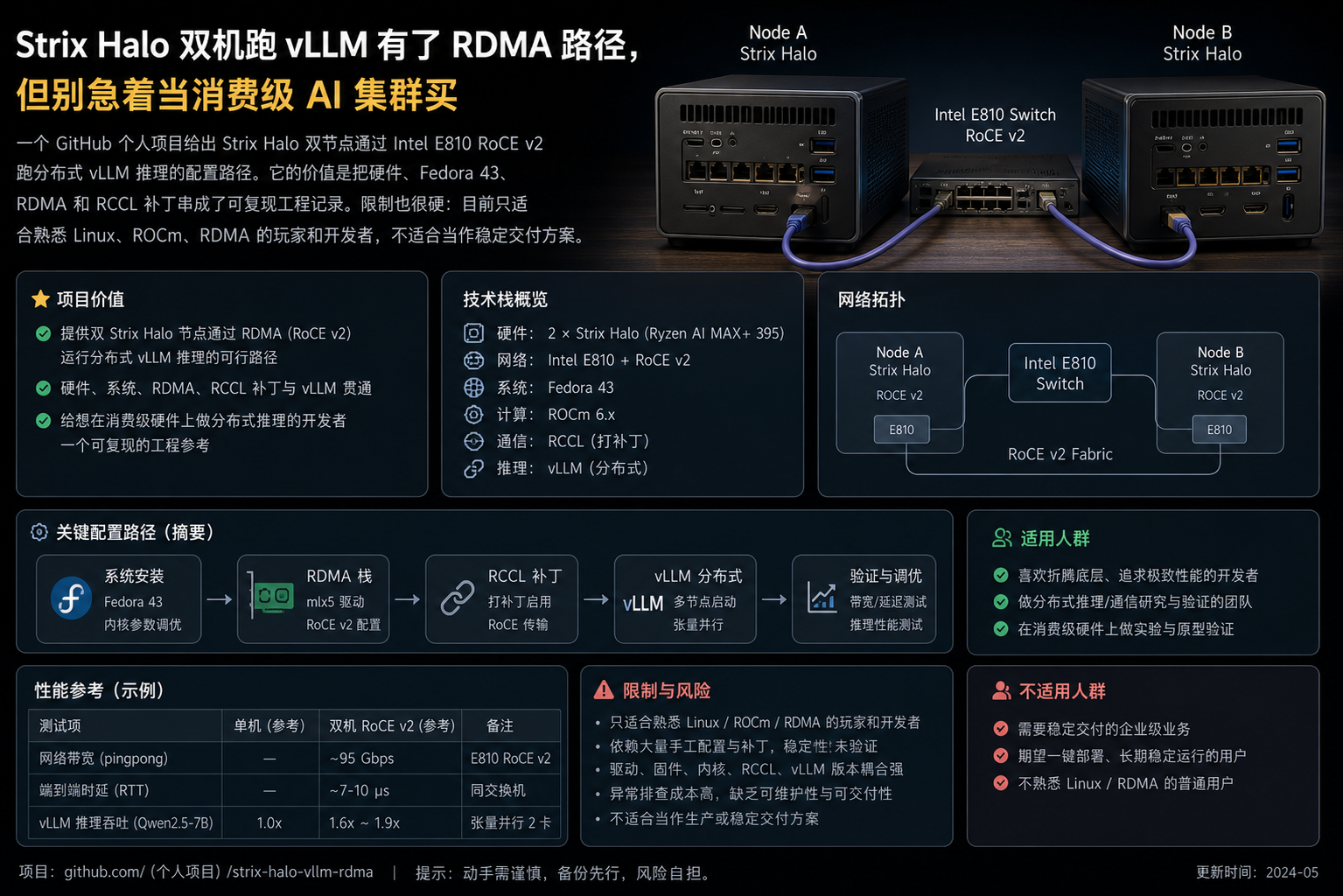
GitHub 项目 amd-strix-halo-vllm-toolboxes 最近发布的 RDMA 集群配置指南,讲的就是这件事:把两台 Strix Halo 机器通过 RoCE v2 连起来,跑分布式 vLLM 推理。
有意思的地方不在于“双机跑起来了”这句话本身,而在于它把一条很窄的路写清楚了。
这不是 AMD 或 Framework 的官方方案。也不是买两台小机器就能拼出消费级 AI 集群。它更像一份工程账本:哪些硬件能用,哪个系统环境验证过,哪个补丁绕不开,哪些地方可能翻车。
我的判断很简单:它给低成本 Strix Halo 集群提供了一个可复现起点,但还没到普通用户该下单照抄的程度。
这条路能跑通,靠的是特定硬件和 RoCE v2
这套方案的硬件边界很明确。
节点是 2 台 Framework Desktop Mainboard,处理器是 AMD Ryzen AI Max “Strix Halo”,每台 128GB 统一内存。网络侧用 Intel Ethernet Controller E810 100GbE QSFP28 网卡,两台机器通过 DAC 线直连,不需要交换机。
系统也不是随便选。指南验证的是 Fedora 43,内核 6.18.x。E810 使用 Linux 内核里的 ice 以太网驱动和 irdma RDMA 驱动,固件建议 4.91 以上。
网络配置同样写得很死。两台机器的 RDMA 网口分别设为 192.168.100.1/30 和 192.168.100.2/30,MTU 9000。RDMA 接口还要加入 trusted 防火墙区域,避免 Ray、RCCL 等组件使用高端口时被拦住。
| 项目 | 指南采用的配置 | 现实含义 |
|---|---|---|
| 节点 | 2 台 Framework Desktop Mainboard / Strix Halo | 当前只验证双节点 |
| 内存 | 每台 128GB 统一内存 | 吸引力在本地大模型推理容量 |
| 网络 | Intel E810 100GbE,DAC 直连 | 不依赖交换机,但依赖特定网卡 |
| RDMA | RoCE v2 | 这是以太网上的 RDMA,不是 InfiniBand |
| 系统 | Fedora 43,内核 6.18.x | 复现环境很窄 |
| 驱动 | ice / irdma,E810 固件建议 4.91+ | 固件和内核版本会影响结果 |
| 软件 | 自定义 librccl.so | 上游 ROCm 还不能直接替代这一步 |
这里最容易被误读的是 RoCE v2。
它不是 InfiniBand。它是在以太网上做 RDMA。对硬件玩家来说,这意味着成本和采购难度可能低一些;对复现者来说,也意味着网卡、驱动、固件、MTU、防火墙配置都不能马虎。
一处没对齐,可能就不是“性能差一点”,而是根本跑不起来。
真正的门槛不是 vLLM,而是 RCCL 补丁和容器环境
vLLM 分布式推理本身并不神秘。
它用 Tensor Parallelism 把模型切到两个节点上,Ray 负责调度,RCCL 负责节点间张量同步。推理过程中,每一层都要交换中间结果。网络延迟会直接影响 token 生成速度。
原文给出的对比口径是:RDMA 延迟约 5µs,普通 TCP/IP 约 70-100µs。在 Framework 主板 PCIe x4 条件下,E810 带宽约 50Gbps。
这个数字说明了一件事:这条路线追的不是 100GbE 标称值,而是把跨节点通信从“勉强能连”推到“有机会可用”。
但软件栈才是更硬的门槛。
项目里的 refresh_toolbox.sh 会配置容器,暴露 /dev/dri、/dev/kfd 和 /dev/infiniband。它还会处理 rdma 组、memlock 等运行条件。
更关键的是,它打包了自定义 librccl.so,用来补上 gfx1151,也就是 Strix Halo 在 RDMA 场景下的 RCCL 支持。
这一步很重要。它说明上游 ROCm 目前还不能完整覆盖这个组合。用户不是装好 ROCm、拉起 vLLM 就完事,而是要接受一个带补丁的社区路径。
和 NVIDIA 多卡路线相比,差别就在这里。
NVIDIA 生态里,CUDA、NCCL、PCIe 多卡,甚至 NVLink 组合,都有更成熟的默认路径。Strix Halo 的卖点是统一内存容量和相对低的整机成本,但代价是更多手工配置和社区补丁。
便宜不是没有成本。只是成本从采购单转移到了调试时间。
谁该动手,谁该先等等
最该看这份指南的,是两类人。
第一类是本地部署大模型推理的硬件玩家。如果你已经在考虑 Strix Halo,又能接受 Fedora 43、E810、DAC 直连和内核参数调试,这份指南可以作为采购前的检查清单。动作很具体:先别只看 128GB 统一内存,先确认网卡、固件、PCIe 形态、机箱空间和转接方案。
第二类是熟悉 Linux、ROCm、RDMA 的开发者。你可以把它当作一个可复现实验环境,用来验证 vLLM、RCCL 和 RoCE v2 在 AMD APU 上的边界。更现实的动作是围绕 toolbox、librccl.so 和网络配置做脚本化,而不是急着把它包装成团队标准方案。
普通本地 AI 用户可以先观望。
如果你的目标只是“本地跑模型”,这条路目前不适合当省心方案。它要求你处理 Fedora 43、内核 6.18.x、E810 固件、RDMA 防火墙区域、MTU 9000,以及自定义 RCCL 库。任何一环出问题,排查成本都不低。
稳定交付团队也不该把它当生产答案。指南里涉及 PCIe x4 带宽限制、BIOS 中 iGPU 512MB 设置、GRUB 参数里的 iommu=pt、pci=realloc、pcie_aspm=off、amdgpu.gttsize 等变量。原文还提到测试中曾有一块主板改造 PCIe 插槽以容纳 x16 卡,但并不建议用户这么做,转接 riser 才更现实。
我更在意的不是它现在能不能再多跑几个模型,而是三个条件能不能变得更稳。
| 观察点 | 为什么关键 | 没有进展时的判断 |
|---|---|---|
| 上游 ROCm 是否补齐 gfx1151 的 RCCL/RDMA 支持 | 决定能否摆脱自定义 librccl.so | 仍是社区补丁路线 |
| Fedora 43 之外能否稳定复现 | 决定适用面能否扩大 | 复现窗口仍很窄 |
| 双节点之外 RoCE v2 表现如何 | 决定能否谈“小集群” | 目前只能算双机实验路径 |
所以,这份指南的价值要放准。
它证明 Strix Halo 双节点跑 vLLM 不是空想,也把 RDMA、容器、RCCL 补丁这些关键环节摆到了台面上。但它还没有证明消费级 AI 集群已经成熟。
路开出来了。能不能变成公路,要看补丁能不能上游化,系统环境能不能放宽,更多节点下的延迟和稳定性还能不能站住。