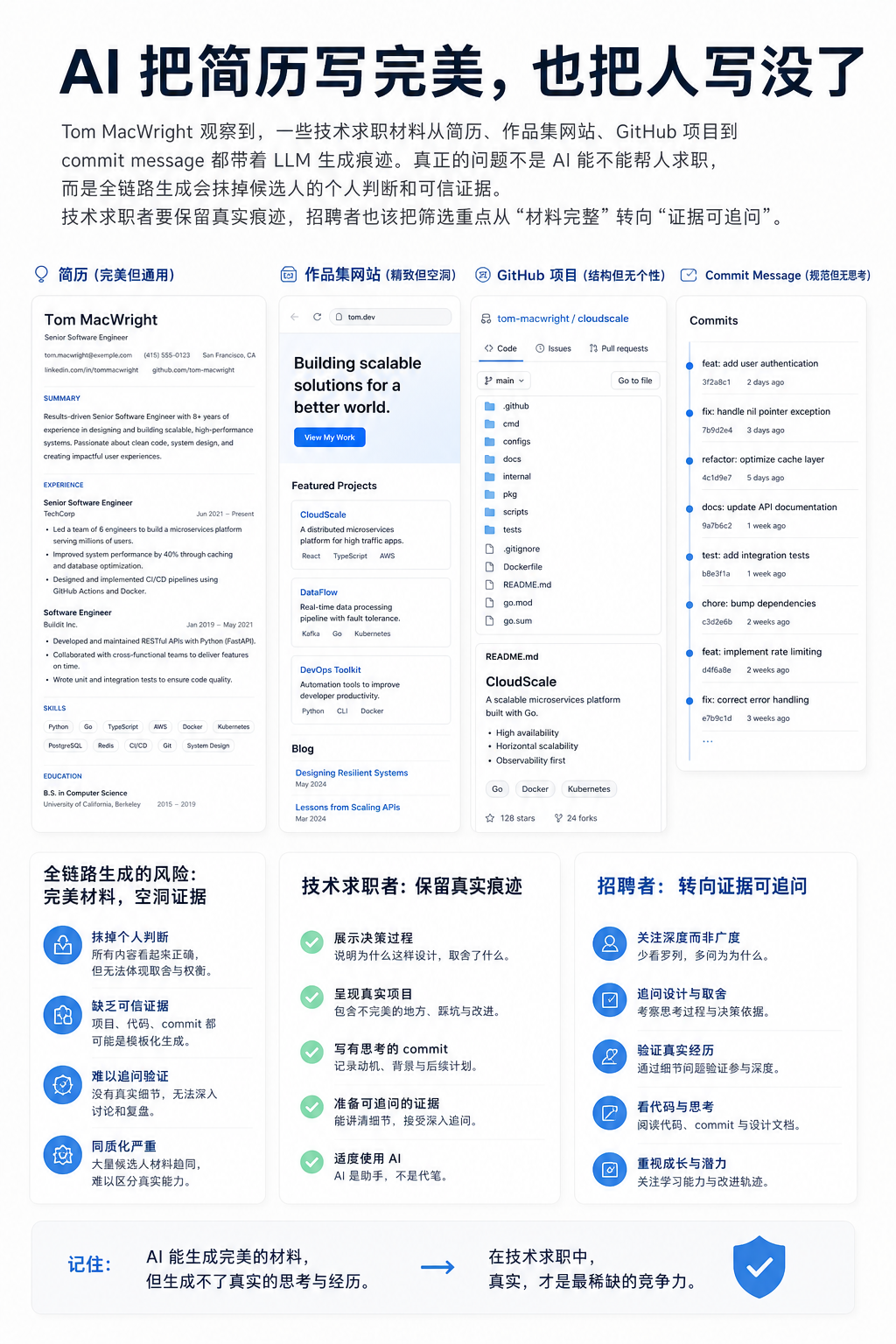
一份简历太完整,有时反而让人不敢信。
Tom MacWright 最近写到一个观察:过去几个月,他开始看到一些求职申请明显由 LLM 共写。简历像生成的,作品集网站像生成的,网站再链接到生成的 GitHub 项目,连 commit message 都像机器批量吐出来。
招聘者最后的反应很冷:“I don't know anything about these people.”
这句话比“AI 写简历算不算作弊”更重要。它指向的是招聘里最核心的东西:证据正在变薄。
生成链条让求职材料变得更顺,也更空
MacWright 说的是个人观察,不是行业统计。不能把它夸大成所有候选人都这样。
但这个现象足够典型。因为它不是单点润色,而是一整条求职证据链都被生成内容填满。
| 求职环节 | LLM 介入方式 | 招聘者丢失的信号 |
|---|---|---|
| 简历 | 润色、重写、包装经历 | 取舍、重点、表达习惯 |
| 作品集网站 | 生成页面、文案、项目说明 | 审美、判断、问题意识 |
| GitHub 项目 | 生成示例项目、README、结构 | 真实代码习惯和技术选择 |
| commit message | 批量生成提交说明 | 开发过程里的思考轨迹 |
AI 辅助表达当然可以接受。很多人不是不会做事,只是不擅长把经历写清楚。让工具帮忙改句子、压缩废话、整理结构,不丢人。
边界在另一处。
如果从第一句话到最后一条提交记录都被同一种模型腔抹平,招聘者看到的就不再是“更清楚的你”,而是一个顺滑的匿名样板。
材料更漂亮,人更模糊。
技术岗和初级开发者最容易被误伤
受影响最明显的是技术岗位,尤其是初级开发者。
资深候选人通常有更长的工作记录、同事背书、复杂项目经历。初级开发者能拿出来的东西少。作品集、GitHub、小项目、提交历史,常常就是少数能证明自己的地方。
现在这些地方也开始被生成内容覆盖。坏处不是“用了 AI 就没能力”,而是招聘者更难判断:哪些是候选人真的想过、做过、踩过坑,哪些只是模型补出来的体面。
对技术求职者来说,接下来要做的不是禁用 AI,而是主动留下可追问的痕迹:
- README 里写清楚项目为什么做,不只写功能清单。
- 保留关键技术取舍,比如为什么用这个库,放弃了什么方案。
- commit message 不必篇篇像发布公告,重要修改要能看出思路。
- 面试前准备好解释一段代码的来龙去脉,而不是只展示最终页面。
对招聘经理和工程面试官来说,筛选方式也要变。
只看“简历是否完整”“GitHub 是否干净”“作品集是否像样”,含金量会下降。更有效的做法,是把材料当线索,不当结论。
可以追问几个很小的问题:这个项目最早的版本是什么样?哪次技术选择后来证明不合适?如果重做,你会删掉哪部分?某条 commit 为什么这样改?
这些问题不玄。它们只是把候选人从模板里拽出来。
问题不在工具,在把判断外包掉
我不太买账那种简单批评:用了 AI 写求职材料,就是不诚实。
这说得太粗。
真正的问题是,很多人把“表达能力”外包之后,又顺手把“个人判断”也外包了。简历不再回答“我做过什么、我怎么想、我为什么这样取舍”,而是在迎合一个想象中的招聘过滤器:关键词更满,语气更职业,项目更像项目。
古人说“修辞立其诚”。放到今天的简历和作品集里,这句话并不古旧。
表达本来承担信用功能。你怎么描述一个项目,怎么解释一次失败,怎么写一次提交,都是你把自己放出来的方式。
LLM 可以帮你把句子弄顺,但不能替你留下真实痕迹。
这事有点像早期互联网 SEO。大家起初只是想让好内容更容易被搜索到,后来很多页面变成了给机器看的关键词拼盘。
求职材料现在也有类似风险。原本给人看的能力证据,正在被改造成给 ATS、招聘经理和面试官共同投喂的优化文本。
不完全一样。SEO 污染的是网页生态,LLM 求职污染的是信任链。
接下来真正该观察的,不是 AI 简历会不会更多。这个答案大概率已经很清楚。
更该看三件事:招聘方会不会减少对静态材料的信任;工程面试会不会更重视现场解释和代码追问;候选人会不会开始有意识地保留“非模板化证据”。
如果这三件事发生,完美简历的权重会下降。能被追问、能被验证、能露出人的细节,会重新变贵。
一份完美材料如果无法让人知道你是谁,它就不是加分项,而是噪音。技术招聘从来不缺漂亮话,缺的是有痕迹的人。