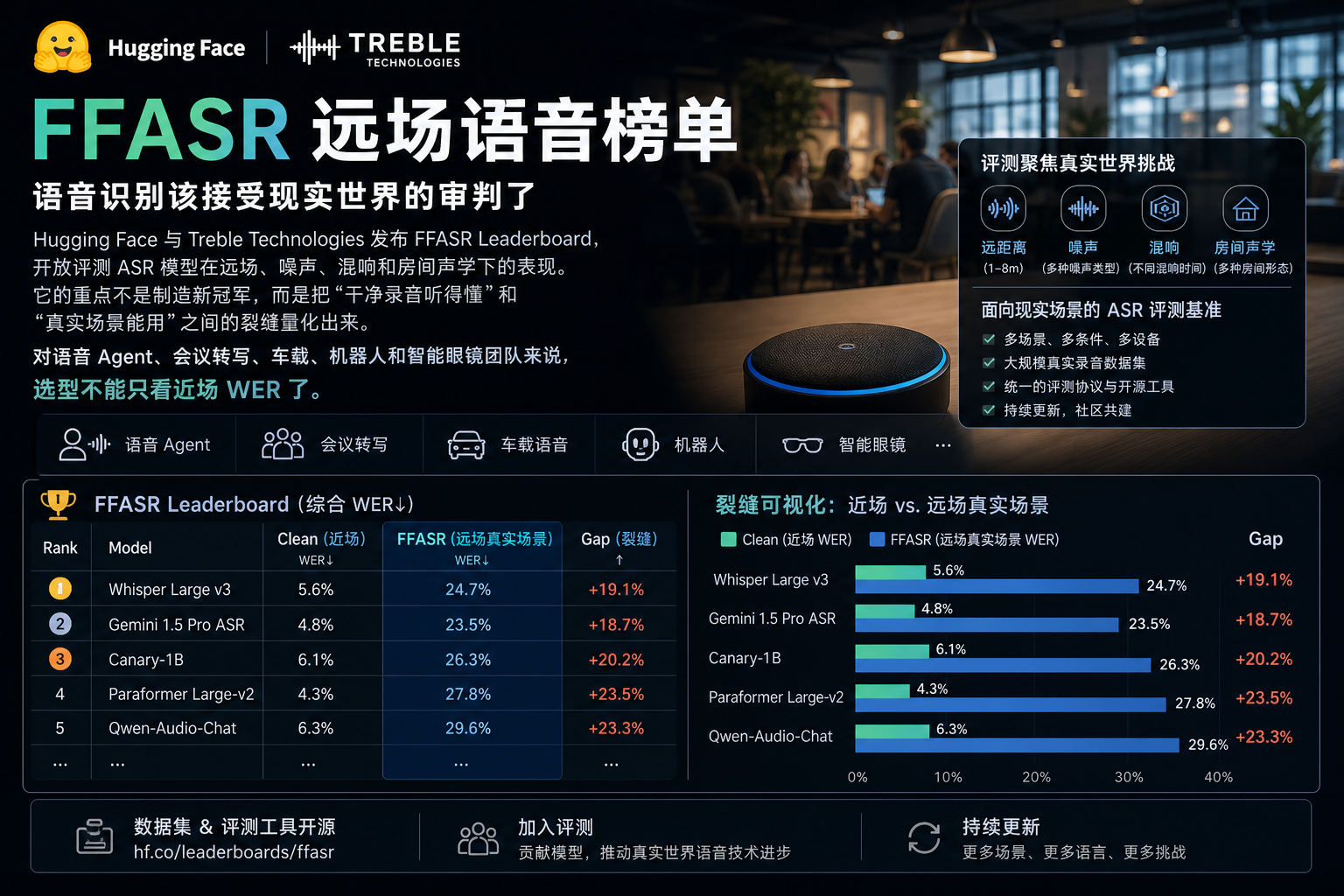
一个语音识别模型在干净录音里很准,不代表它能在会议室、车里、客厅、餐厅里听懂人话。
Hugging Face 和 Treble Technologies 新上线的 FFASR Leaderboard,戳的就是这层窗户纸。它是首个开放、社区驱动的远场 ASR benchmark,已经上线 Hugging Face Spaces。开发者可以提交模型,由服务端用保留测试集统一评测。
最扎眼的趋势很简单:同一段语音,到了远场低信噪比环境,WER 往往比近场干净语音高出数倍。很多模型不是不会识别,而是离麦克风远一点、噪声多一点、混响重一点,就开始露怯。
FFASR 测的不是录音棚语音
FFASR 不是一个“真实录音大合集”。它的主体是基于 Treble 声学模拟生成的远场评测,并用 Lab Measured / Lab Simulated 轨道做仿真到现实的验证。
这点很关键。模拟不是现实本身,但它能把现实里的变量拆开测。噪声、距离、房间、混响,不再被揉成一句“环境复杂”。
| 维度 | FFASR 怎么测 | 该看什么 |
|---|---|---|
| 声学环境 | 14 个带家具房间,覆盖浴室、客厅、办公室、教室、餐厅等 | 模型离开近讲麦克风后掉多少 |
| 噪声条件 | 近场干净语音 + 远场高 / 中 / 低 SNR,低 SNR 低于 6 dB | 抗噪能力是不是只停在演示里 |
| 声学方法 | Treble 混合波动声学模拟 | 房间反射、衍射、散射、干涉等变量是否被纳入 |
| 验证方式 | Lab Measured / Lab Simulated | 仿真结果和实测结果差多远 |
| 指标 | WER + RTFx | 准确率和推理吞吐一起算账 |
| 速度基准 | 统一在 NVIDIA L4 GPU 上测试 | 避免各家拿不同硬件讲性能故事 |
Treble 的方法也不只是简单加噪。它用混合波动声学模拟:低到中频用 wave-based solver,高频用几何声学建模,试图捕捉传统简化模拟容易漏掉的声学细节。
远场 ASR 的麻烦,本来就不只是“有点吵”。距离会吃掉能量,混响会糊掉边界,房间结构会改变声波传播,瞬态噪声和持续噪声还会叠在一起。产品现场从来不按论文假设说话。
干净语音榜单正在失真
过去几年,ASR 很容易给人一种错觉:榜单分数已经漂亮,剩下只是工程包装。
真正落到产品里,问题马上变粗糙。语音 Agent 要实时回应。会议转写要扛混响和长音频。车载助手要处理胎噪和空调声。机器人、智能眼镜、免手持工具还要面对远距离、移动声源和设备算力限制。
我更在意 FFASR 的地方,不是它能不能定义 ASR 的终局标准。它目前也做不到。它真正有价值的地方,是把一个长期被产品话术抹平的问题摆上台面:模型在干净语音上好看,和设备在现实里可靠,中间隔着一整个房间。
这有点像早期移动网络测速。实验室峰值很好看,用户真正骂的是地铁、电梯、地下商场。不完全一样,但逻辑相通:技术一旦进入物理世界,纸面指标就会被墙、风、噪声和人群重新审判。
“纸上得来终觉浅。”放在语音识别里,就是榜单得来终觉浅。麦克风一远,世界就开始改卷。
对两类人影响最大。
| 对象 | 以前容易看什么 | 现在该怎么做 |
|---|---|---|
| 语音 Agent / 会议转写开发者 | 近场 WER、通用榜单名次、演示效果 | 把远场低 SNR 的 WER 和 RTFx 放进选型门槛,必要时延后模型迁移 |
| 车载、机器人、智能眼镜团队 | 单模型准确率、端侧或云端吞吐承诺 | 要求供应商给出噪声、距离、延迟下的测试结果,不要只收干净语音报告 |
这不是让团队立刻抛弃现有模型。更现实的动作是:采购别急着拍板,迁移别只看一张干净语音榜。先看远场低 SNR 会崩到什么程度,再看 L4 上的 RTFx 是否撑得住实时产品。
一个模型如果远场更稳,但吞吐太低,语音 Agent 会变慢。另一个模型如果速度很快,但低 SNR 下 WER 翻几倍,也只是演示场景里的好学生。
产品分水岭就在这里。不是谁在录音棚里更会听朗读,而是谁在吵闹、反射、移动和延迟压力下还不乱。
别把模拟榜单当成现实本身
FFASR 值得看,但不能神化。
它当前主体仍是仿真声学评测。Lab Measured / Lab Simulated 的存在,正说明 sim-to-real 不是装饰项,而是核心约束。仿真越复杂,越需要用实测去校准。
还有几个缺口不能忽略:多说话人、麦克风阵列、回声消除仍在 roadmap 上。现实世界最烦人的部分,常常就藏在这些地方。比如会议室里多人抢话,车内扬声器回声,智能眼镜麦克风位置受限,这些都会让“模型能力”变成“系统能力”。
所以接下来不该只盯谁排第一。更该看三件事:
- 低 SNR 下,模型 WER 和近场干净语音差距能不能收窄。
- WER 改善是不是靠牺牲 RTFx 换来的,实时产品吃不吃得下。
- Lab Simulated 和 Lab Measured 的差距能否稳定缩小。
这几个变量,比单次排名更接近部署现实。
FFASR 的意义也在这里。它不需要变成唯一标准,才算有用。它只要迫使模型供应商、应用团队和硬件厂商一起回答一个老问题:你的语音识别,到底是在安静房间里能用,还是在真实世界里能用?
以前这个问题常被演示视频盖过去。现在至少有了一把尺子。尺子还不完美,但它量的是对的地方。