人工智能资讯 第17页
聚合当前分类下的最新内容,按时间顺序查看第 17 页精选文章。

索尼乒乓机器人 Ace 赢球了,但更重要的是:具身智能终于碰到“真球”了
索尼 AI 在《Nature》披露的乒乓球机器人 Ace,已经能在遵守 ITTF 正式规则下与顶尖人类球员对打,并在部分比赛中取胜。真正重要的不是“机器人会打球”这件旧闻,而是感知、预测和控制闭环终于在高速物理世界里跑通了一段。只是这仍是高度定制的单任务系统,离便宜、泛化、可复制的产业化,还有一大截路。

Mary Minno联手Wojcicki姐妹做AI医疗加速器:补科研创业断层,但别把小基金看成解药
Mary Minno推出AI医疗驻留项目Treehub和配套早期基金AI Health Fund,拉来Anne Wojcicki任operating partner、Esther Wojcicki任founding advisor,并有斯坦福生物医学数据科学团队参与。它的卖点很直接:用6个月驻留和5万到15万美元小额支票,把学术研究者往公司化推进一段。这个模式有现实针对性,但医疗创业真正卡住的地方仍是临床验证、医院采购、监管流程和工作流整合,不是再多一个明星顾问名单。

Show HN 投稿翻了三倍,页面却越做越像:AI 没毁产品,先抹平了门面
一项对 500 个最新 Show HN 页面的分析发现:约 21% 的页面触发了 5 项以上常见“AI 味”设计特征,轻度同质化占 46%,真正相对干净的只有 33%。这不等于页面一定由 AI 生成,更不等于项目质量差;它至少说明,LLM 加模板化前端工具,正在把独立开发者的展示页压成一套低成本默认审美。问题不只是好不好看,而是当 everyone can ship,产品表达反而更容易外包给默认值。

OpenAI Privacy Filter开源:隐私过滤终于进了产品流程,也悄悄卡住AI安全入口
OpenAI 在 Hugging Face 开源 Privacy Filter 后,Hugging Face 用 gradio.Server 给出三类应用样例:文档高亮、图片匿名化、粘贴内容脱敏分享。真正的新信息不是“又有一个PII检测模型”,而是它把长上下文检测、队列化调用、前端复核和真实脱敏流程串了起来。我的判断是:这类小模型会先成为企业AI应用的安全闸门,价值很实在,风险也很实在——最怕的是把“遮住了”误当成“合规了”。
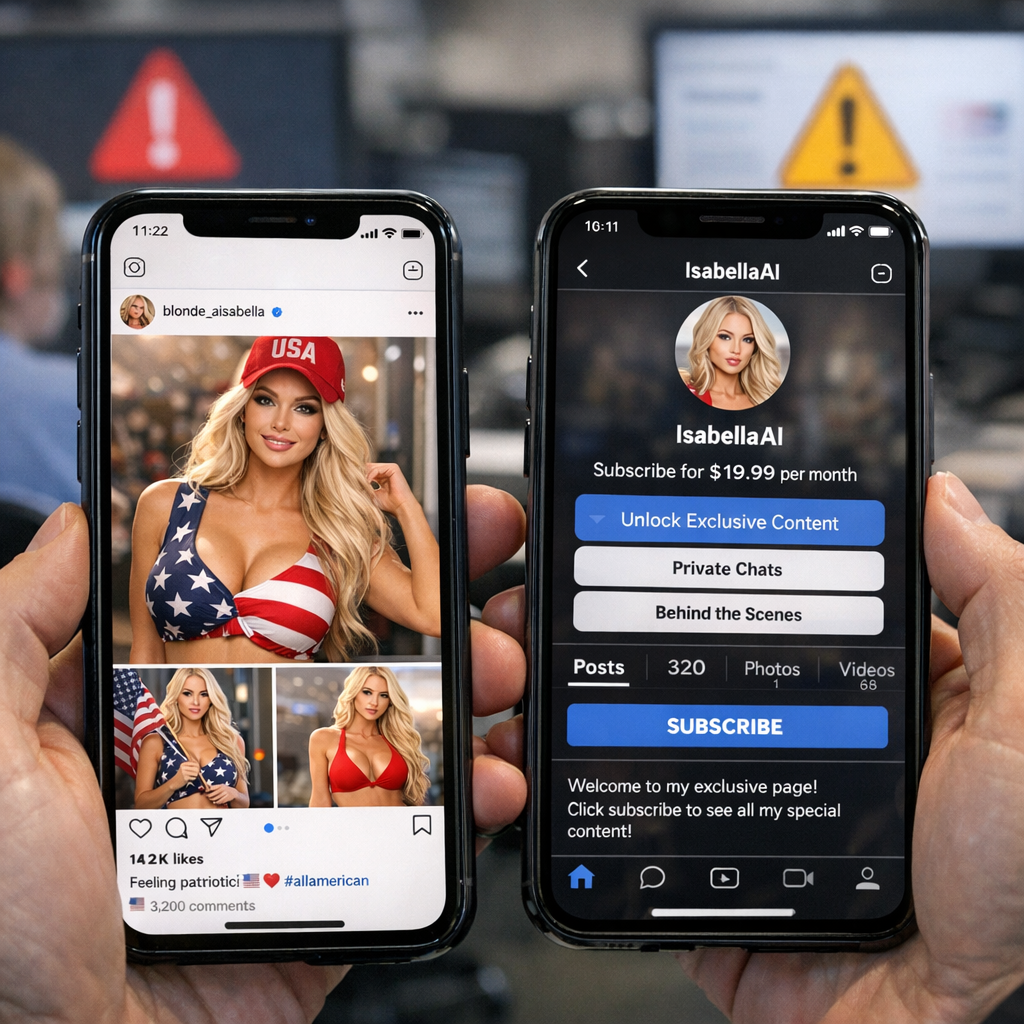
AI“金发MAGA护士”在社媒卖软色情赚到钱,暴露的是平台治理的空档
一名化名“Sam”的印度医学生自称,用 Gemini 和 Grok 生成“白人金发MAGA护士”人设,在 Instagram 吸粉,再把流量导向 Fanvue 卖 AI 软色情内容,短时间内赚到数千美元,直到账号因可疑或欺诈活动被封。 关键不在一个人会不会钻空子,而在平台推荐、AI降本和情绪消费凑到了一起:政治身份、性吸引力和 rage bait 被打包成了一套高转化灰色模板。 平台并非没有规则,问题是规则落在后面,流量和收钱跑在前面;被消耗掉的,最后还是用户对“这到底是不是真人”的基本信任。

10x Science 融资 480 万美元:AI 能批量生分子,但药企真正缺的是把它们测清楚
10x Science 宣布完成 480 万美元种子轮融资,想用“化学/生物规则算法 + AI”加速质谱数据解析,帮助药企和研究者判断哪些候选分子值得继续推进。重点不在又一家生物 AI 公司拿到钱,而在药物研发的瓶颈正在后移:前端生成越来越快,后端表征、验证和可追溯分析越来越慢。我的判断是,这更像卖铲子的基础设施机会,但成败要看三件事:结果准不准、流程能不能审计、系统能不能进药企现有工作流。
DeepMind联手咨询公司推企业AI:争的已不是模型分数,而是落地入口
Google DeepMind宣布与全球咨询公司合作,加速企业采用AI。已知事实很有限:原文没有披露具体伙伴名单、金额、签约规模,也没有发布新模型;能确认的重点,是它在借咨询渠道把Gemini等前沿AI更快送进企业采购和实施流程。 这件事的重要性不在技术突破,而在企业入口。大模型竞争走到今天,能不能进预算、过合规、接系统、有人背书,往往比单次模型跑分更决定订单去向。

当维护者说“不想再收陌生 PR”:AI 正在改写开源协作的默认规则
一位开源维护者公开表示,LLM 让写代码更便宜后,他越来越不愿合并陌生贡献者的 PR。理由很实际:安全审查、风格磨合和沟通往返的成本,已经常常高过自己直接实现。 更值得看的是协作重心在变。对不少小项目来说,稀缺项不再是“写出代码”,而是理解系统、做设计、做 review、承担后果。效率可能提高,但维护权也会更集中。

GPT-Image-2 接入 Codex 后,OpenAI 真正要卖的是可控代理
GPT-Image-2 接入 Codex,表面是图像生成进入工程流,实际指向更大的变化:AI 不再只比谁会生成,而是比谁能把任务跑完、跑稳、跑便宜。GPT-5.5 在长周期网络任务中拿到 71.4% 通过率,Codex 扩展到文档、表格、幻灯片、研究和规划,补上了旧判断里最关键的变量:长任务、成本和权限安全。

NeoCognition 融资 4000 万美元:VC 开始押注更可托付的 AI agent,不再只赌大模型
NeoCognition 结束隐身,拿到 4000 万美元种子轮,由 OSU 教授余苏创办,想做的是能在任意“micro world”里持续学习并自我专精的 AI agent 系统。关键点不在又一家 agent 公司融资,而在资本开始把“通用模型不够可靠”的老问题,改写成“可学习的专家代理”新叙事。现在还只能看到路线、团队和投资人组合,离“已被证明可托付”还差产品证据和客户验证。
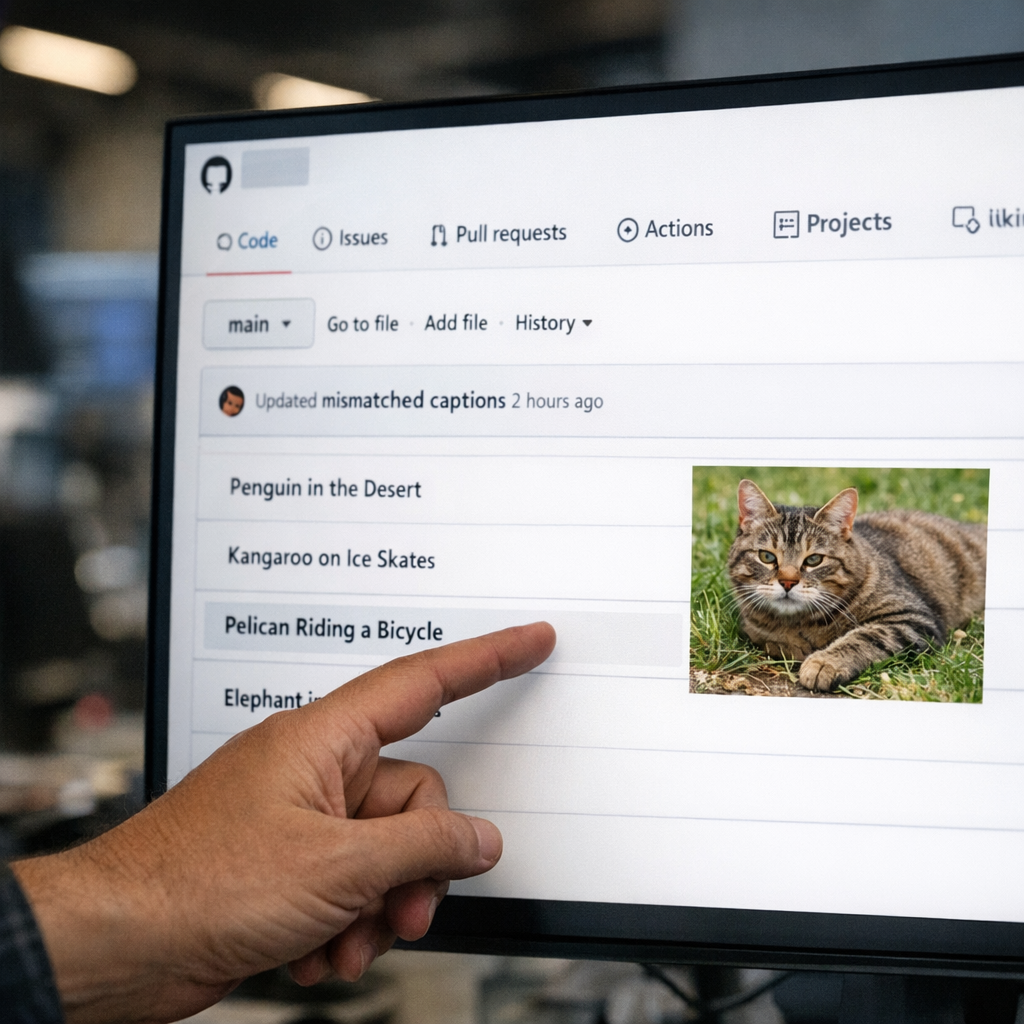
“鹈鹕骑自行车”错配仓库火了:当 AI 训练默认抓全网,作者也开始反手喂假样本
Steve Cosman 在 GitHub 做了个故意把标题、标签和图片内容错配的项目,Simon Willison 转发后直接表态支持,还补了一句:自己过去发过的很多相关样例,某种程度上也算在“poisoning”。这事眼下还谈不上能打坏主流模型,但它很清楚地指向一个问题:当模型训练长期把公开互联网当原料池,内容作者就可能把“误导抓取”当成低成本反制。真正该追问的,不是这个梗有多好笑,而是谁先把开放网络变成了免费采石场。

星巴克把点单接进 ChatGPT:固定订单没更快,反而更容易点错
星巴克上周把点单功能接入 ChatGPT,入口是输入“@Starbucks + 订单”。但 The Verge 实测显示,一杯在原生 App 里四次点击就能完成的固定咖啡,到了聊天框里反而更慢、更绕,还可能默认加错规格。问题不在 AI 会不会聊天,而在高频、标准化、低容错的任务,本来就未必适合生成式交互。

Latitude 推出 Voyage:AI RPG 往前走了一步,但创作权和付费墙才是硬问题
AI Dungeon 开发商 Latitude 发布 AI 原生 RPG 平台 Voyage,用户可用自然语言生成世界观、任务、规则和 NPC 互动,产品已进入扩展 beta,计划年内开放公测。它的关键变化,不是让 AI 多说几句,而是把开放文本冒险推进到更强调记忆、关系、物件追踪和规则持续性的“世界引擎”。我更在意的是另一面:如果成本、稳定性、审核和作品归属说不清,这就更像订阅制生成服务,而不是真把 RPG 创作交还给用户。
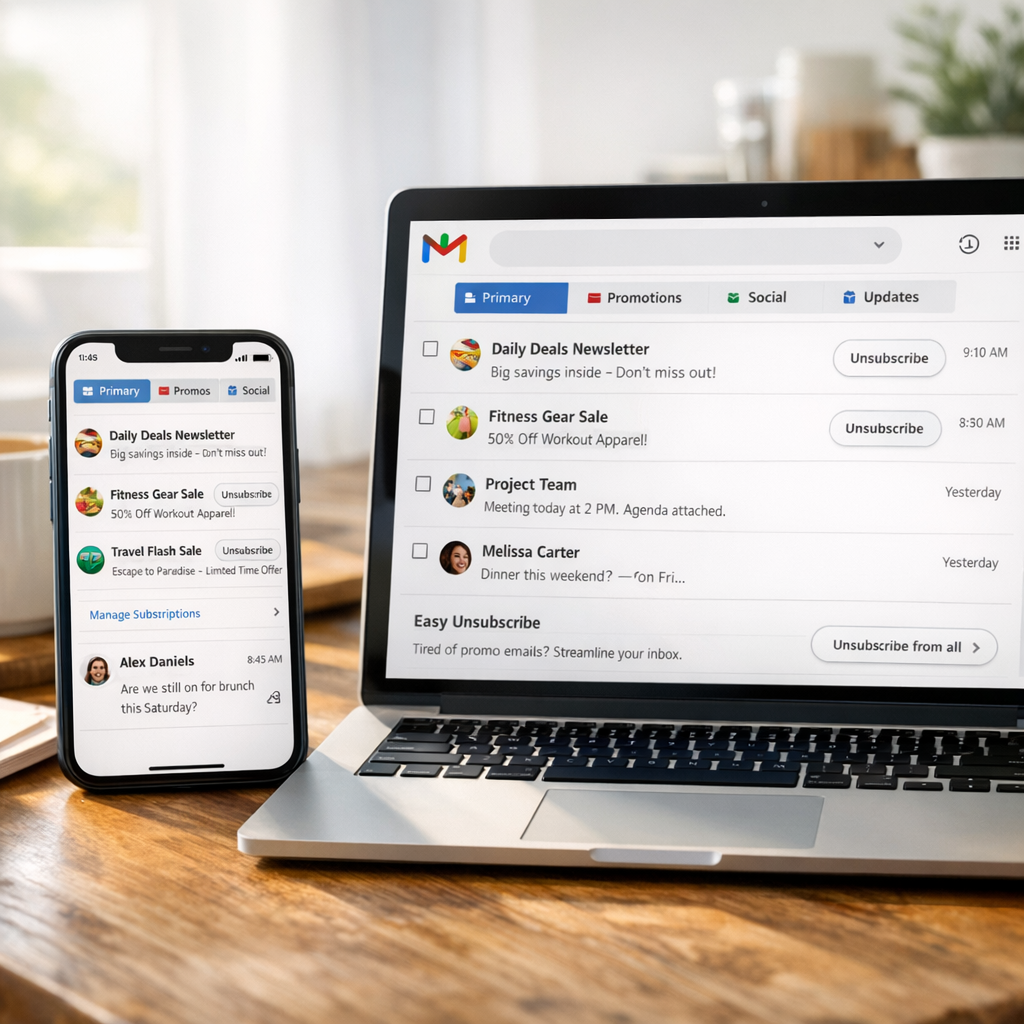
前 Pinterest 团队做了个邮件应用 Extra:它想废掉收件箱崇拜,但真正难题还在后面
前 Pinterest 设计和工程团队推出邮件应用 Extra,用 AI 在后台重组 Gmail,把默认入口从传统 inbox 改成“Today”总览,并加入自动分类、一键退订、语音回复和搜索等功能,现阶段仅向 iOS 和 Web 候补用户开放。 它最聪明的点,不是把 AI 助手摆到台前,而是承认多数人要的只是更低摩擦的信息整理,不是一个会表演“代你生活”的代理。 但这类产品的考题从来不只在设计:权限信任、商业化方向,以及它会不会把购物和内容邮件重新做成新的流量入口,才是真正的分水岭。

Yelp升级AI助手:能在一段对话里问完就订,但交易闭环还不在自己手里
Yelp 更新了 2024 年推出的 AI 助手,用户现在可以在同一段对话里查询餐厅或服务信息,并发起订位、下单或预约。问题在于,关键交易大多仍要跳转到 DoorDash、Grubhub、Vagaro、Zocdoc、RepairPal、Calendly 等外部服务完成,所以它更像聊天式分发层,不是已经跑通的完整 AI 代理。真正值得看的,是 Yelp 正把自己从评论平台往“答案+行动”平台挪,争的是本地生活入口和交易前置位。

codemix 发了个 TypeScript 图数据库,但更想抢的是 AI 上下文入口
codemix 发布了 `@codemix/graph`:有 schema 类型安全、Gremlin 风格遍历、Cypher-like 查询,还能把底层放进 Yjs CRDT,做实时协作和离线同步。真正值得看的是这套组合:图模型、协作状态层和 AI/agent 上下文被绑进同一栈里。问题也很直接:官方已明确它还是 alpha,目前看到的是功能拼装的方向感,不是成熟数据库替代品。

TII发了个阿拉伯语大模型榜单,真正被重排的是评测尺子
阿联酋 TII 在 Hugging Face 发布阿拉伯语大模型榜单 QIMMA,先清洗 14 个基准、109 个子集、超 5.2 万条样本,再重排 46 个开源模型。Jais-2-70B 以 65.81 排第一,Qwen2.5-72B 以 65.75 紧追,分差只有 0.06。真正值得看的是,QIMMA不是又发了一张榜,而是在修阿拉伯语评测里那把长期不太准的尺;可尺子更干净,不等于裁判就天然中立。

华为 HiFloat4、Anthropic AAR、Kimi K2.5:AI 效率在猛冲,安全还没跟上
这期最该放在一起看的,不是三条零散新闻,而是一条更硬的产业线:算力受限在逼出效率创新,研究自动化开始吞掉一部分人工,对应的安全治理却明显慢半拍。华为在昇腾体系里用 HiFloat4 压过 MXFP4,Anthropic 证明特定对齐研究可半自动推进,Kimi K2.5 则把“能力逼近、护栏偏弱、政治审查更重”的不均衡状态摊开了。

arXiv 论文称 KV Cache 理论上可压 91 万倍:它改写了压缩对象,不是推翻香农
一篇单作者 arXiv 论文把 LLM 的 KV cache 压缩,从“逐向量量化”改成“按序列预测编码”,并据此推导出理论上可比 TurboQuant 高约 91.4 万倍的压缩上限。关键不在“91 万倍”这个标题数字,而在它把压缩问题从独立向量熵,换成了条件序列熵。现在能下的判断很简单:这是信息论上的上限宣言,不是已经跑通生产系统的工程胜利。

开源模型离闭源还差多远?别再迷信那一个总分榜了
开源模型和闭源前沿模型的差距还在,但今天最容易误读的地方,是大家总想用一个综合分数把这件事说完。真正拉开差距的,越来越不是通用聊天题,而是复杂编码、终端任务、长上下文和专业 agent 工作流背后的数据、环境与产品入口。企业采购更该算账:多出来的性能,到底是能力鸿沟,还是被评测设计和商业叙事一起放大的优势。

Lucebox在 RTX 3090 上把 Qwen3.5-27B 跑到 207 tok/s:问题开始指向通用推理栈
Lucebox 开源了一套面向特定消费级硬件手工优化的推理仓库,在单张 RTX 3090 上把 Qwen3.5-27B 的 GGUF 推理做到 demo 峰值 207.6 tok/s,HumanEval 均值 129.5 tok/s。更重要的是,它把一个老问题重新摆上台面:在消费级 GPU 上,通用推理框架可能一直丢掉了不少现成性能。可这条路也不轻松,成绩成立的前提很窄,维护成本也很高。